In a sharded cluster of replica sets, which server or servers handle each of your queries? What about each insert, update, or command? If you know how a MongoDB cluster routes operations among its servers, you can predict how your application will scale as you add shards and add members to shards.
Operations are routed according to the type of operation, your shard key, and your read preference. Let’s set up a cluster and use the system profiler to see where each operation is run. This is an interactive, experimental way to learn how your cluster really behaves and how your architecture will scale.
Setup
You’ll need a recent install of MongoDB (I’m using 2.4.4), Python, a recent version of PyMongo (at least 2.4—I’m using 2.5.2) and the code in my cluster-profile repository on GitHub. If you install the Colorama Python package you’ll get cute colored output. These scripts were tested on my Mac.
Sharded cluster of replica sets
Run the cluster_setup.py script in my repository. It sets up a standard sharded cluster for you running on your local machine. There’s a mongos, three config servers, and two shards, each of which is a three-member replica set. The first shard’s replica set is running on ports 4000 through 4002, the second shard is on ports 5000 through 5002, and the three config servers are on ports 6000 through 6002:
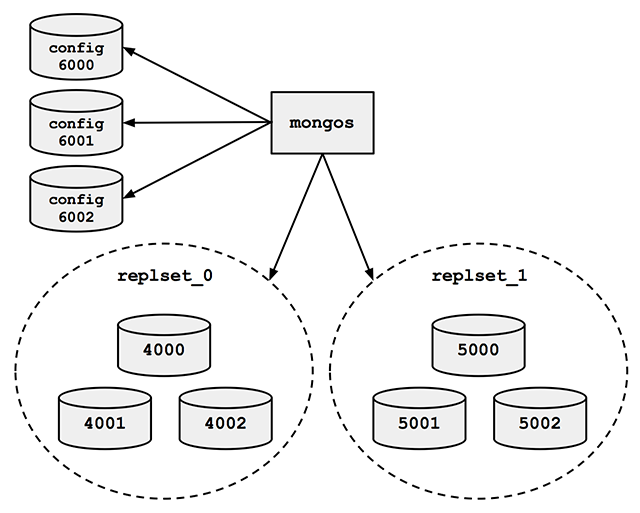
For the finale, cluster_setup.py makes a collection named sharded_collection, sharded on a key named shard_key.
In a normal deployment, we’d let MongoDB’s balancer automatically distribute chunks of data among our two shards. But for this demo we want documents to be on predictable shards, so my script disables the balancer. It makes a chunk for all documents with shard_key less than 500 and another chunk for documents with shard_key greater than or equal to 500. It moves the high chunk to replset_1:
client = MongoClient() # Connect to mongos.
admin = client.admin # admin database.
# Pre-split.
admin.command(
'split', 'test.sharded_collection',
middle={'shard_key': 500})
admin.command(
'moveChunk', 'test.sharded_collection',
find={'shard_key': 500},
to='replset_1')If you connect to mongos with the MongoDB shell, sh.status() shows there’s one chunk on each of the two shards:
{ 'shard_key' : { '$minKey' : 1 } } -->> { 'shard_key' : 500 } on : replset_0 { 't' : 2, 'i' : 1 }
{ 'shard_key' : 500 } -->> { 'shard_key' : { '$maxKey' : 1 } } on : replset_1 { 't' : 2, 'i' : 0 }The setup script also inserts a document with a shard_key of 0 and another with a shard_key of 500. Now we’re ready for some profiling.
Profiling
Run the tail_profile.py script from my repository. It connects to all the replica set members. On each, it sets the profiling level to 2 (“log everything”) on the test database, and creates a tailable cursor on the system.profile collection. The script filters out some noise in the profile collection—for example, the activities of the tailable cursor show up in the system.profile collection that it’s tailing. Any legitimate entries in the profile are spat out to the console in pretty colors.
Experiments
Targeted queries versus scatter-gather
Let’s run a query from Python in a separate terminal:
>>> from pymongo import MongoClient
>>> # Connect to mongos.
>>> collection = MongoClient().test.sharded_collection
>>> collection.find_one({'shard_key': 0})
{'_id': ObjectId('51bb6f1cca1ce958c89b348a'), 'shard_key': 0}tail_profile.py prints:
replset_0 primary on 4000: query test.sharded_collection {“shard_key”: 0}
The query includes the shard key, so mongos reads from the shard that can satisfy it. Adding shards can scale out your throughput on a query like this. What about a query that doesn’t contain the shard key?:
>>> collection.find_one({})mongos sends the query to both shards:
replset_0 primary on 4000: query test.sharded_collection {“shard_key”: 0}
replset_1 primary on 5000: query test.sharded_collection {“shard_key”: 500}
For fan-out queries like this, adding more shards won’t scale out your query throughput as well as it would for targeted queries, because every shard has to process every query. But we can scale throughput on queries like these by reading from secondaries.
Queries with read preferences
We can use read preferences to read from secondaries:
>>> from pymongo.read_preferences import ReadPreference
>>> collection.find_one({}, read_preference=ReadPreference.SECONDARY)tail_profile.py shows us that mongos chose a random secondary from each shard:
replset_0 secondary on 4001: query test.sharded_collection {“$readPreference”: {“mode”: “secondary”}, “$query”: {}}
replset_1 secondary on 5001: query test.sharded_collection {“$readPreference”: {“mode”: “secondary”}, “$query”: {}}
Note how PyMongo passes the read preference to mongos in the query, as the $readPreference field. mongos targets one secondary in each of the two replica sets.
Updates
With a sharded collection, updates must either include the shard key or be “multi-updates”. An update with the shard key goes to the proper shard, of course:
>>> collection.update({'shard_key': -100}, {'$set': {'field': 'value'}})replset_0 primary on 4000: update test.sharded_collection {“shard_key”: -100}
mongos only sends the update to replset_0, because we put the chunk of documents with shard_key less than 500 there.
A multi-update hits all shards:
>>> collection.update({}, {'$set': {'field': 'value'}}, multi=True)replset_0 primary on 4000: update test.sharded_collection {}
replset_1 primary on 5000: update test.sharded_collection {}
A multi-update on a range of the shard key need only involve the proper shard:
>>> collection.update({'shard_key': {'$gt': 1000}}, {'$set': {'field': 'value'}}, multi=True)replset_1 primary on 5000: update test.sharded_collection {“shard_key”: {“$gt”: 1000}}
So targeted updates that include the shard key can be scaled out by adding shards. Even multi-updates can be scaled out if they include a range of the shard key, but multi-updates without the shard key won’t benefit from extra shards.
Commands
In version 2.4, mongos can use secondaries not only for queries, but also for some commands. You can run count on secondaries if you pass the right read preference:
>>> cursor = collection.find(read_preference=ReadPreference.SECONDARY) >>> cursor.count()
replset_0 secondary on 4001: command count: sharded_collection
replset_1 secondary on 5001: command count: sharded_collection
Whereas findAndModify, since it modifies data, is run on the primaries no matter your read preference:
>>> db = MongoClient().test
>>> test.command(
... 'findAndModify',
... 'sharded_collection',
... query={'shard_key': -1},
... remove=True,
... read_preference=ReadPreference.SECONDARY)replset_0 primary on 4000: command findAndModify: sharded_collection
Go Forth And Scale
To scale a sharded cluster, you should understand how operations are distributed: are they scatter-gather, or targeted to one shard? Do they run on primaries or secondaries? If you set up a cluster and test your queries interactively like we did here, you can see how your cluster behaves in practice, and design your application for future growth.
| Reference: | Real-time Profiling a MongoDB Sharded Cluster from our WCG partner Jesse Davis at the A. Jesse Jiryu Davis blog. |
