This is one of the most frequent questions I’m asked by Heroku Ruby customers: “How do I debug a memory leak?”
Memory is important. If you don’t have enough of it, you’ll end up using swap memory and really slowing down your site.
So what do you do when you think you’ve got a memory leak?
What you’re most likely seeing is the normal memory behavior of a Ruby app. You probably don’t have a memory leak.
We’ll work on fixing your memory problems in a minute, but we have to cover some basics first.
As your app boots up, it consumes a base amount of RAM. It continues to grow as it serves pages until it levels off. This curve looks something like a horizontally asymptotic function:
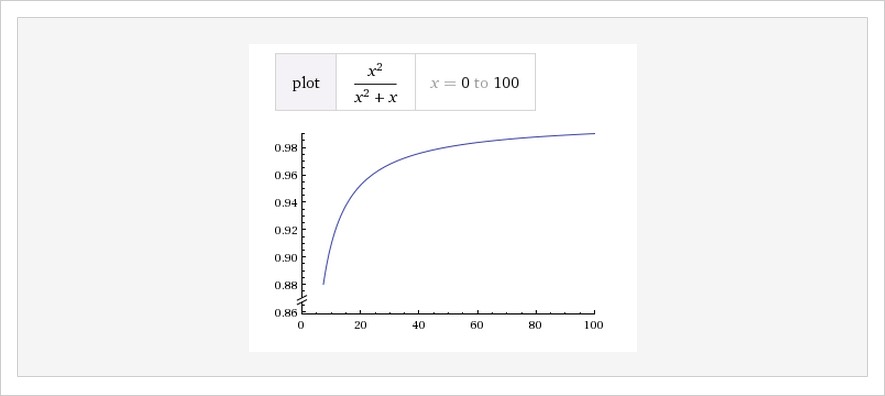
While the value does go up over time, it plateaus and eventually hovers around a stable point. A true memory leak does not level off and continues to increase indefinitely over time. The reason most people think this is a memory leak is they’re only viewing a small slice of the data. If you zoom in far enough to the same curve, it doesn’t look like it plans on stopping:
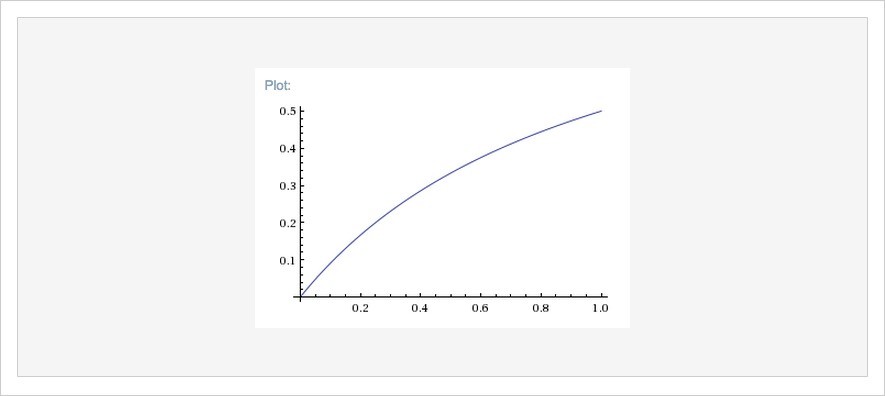
If your app is using more memory than it should, but it doesn’t indefinitely continue to consume memory forever, then you’ve got memory bloat.
Reducing Process Count: The Lowest Hanging Fruit
If you’re running a Ruby app in production, it needs to be running on a concurrent webserver. That’s a webserver capable of handling multiple requests simultaneously. Heroku recommends the Puma webserver. Most modern concurrent webservers allow you to run multiple processes to gain concurrency. Puma calls these “workers,” and you can set this value in your config/puma.rb file:
workers Integer(ENV['WEB_CONCURRENCY'] || 2)
Every time you increase your WEB_CONCURRENCY value, you gain additional processing power but at the expense of more memory. If your app is going over your RAM limits and hitting swap, the easiest thing is to scale down the number of workers you’re using; say, going from four workers to three or from two workers to one (assuming you’re still getting parallelism via threads).
You’ll notice however, that going from four processes to three won’t cut your memory use by one fourth. This is because modern versions of Ruby are Copy on Write friendly. That is, multiple processes can share memory as long as they don’t try to modify it. For example:
# Ruby 2.2.3
array = []
100_000_000.times do |i|
array << i
end
ram = Integer(`ps -o rss= -p #{Process.pid}`) * 0.001
puts "Process: #{Process.pid}: #{ram} mb"
Process.fork do
ram = Integer(`ps -o rss= -p #{Process.pid}`) * 0.001
puts "Process: #{Process.pid}: #{ram} mb"
endWhen we run this, the first process uses hundreds of megabytes of memory. However our forked process is super small:
Process: 99526: 788.584 mb Process: 99530: 1.032 mb
This is a contrived example that shows forked processes are smaller. In the case of Puma, forked workers will be smaller but certainly not by a factor of 1/788.
Running with fewer workers has downsides — most importantly, your throughput will go down. If you don’t want to run with fewer workers, then you’ll need to find hotspots of object creation and figure out how to get around them.
Rolling Restarts
Since your app will slowly grow in memory over time, we can stop it from growing too big by restarting the workers periodically. You can do this with Puma Worker Killer. First, add the gem to your Gemfile:
gem 'puma_worker_killer'
Then in an initializer, such as config/initializers/puma_worker_killer.rb, add this:
PumaWorkerKiller.enable_rolling_restart
If your memory bloat is extremely slow, that code will restart your workers every 12 hours. If your memory increases faster, you can set a smaller restart duration.
This is a Band-Aid for larger overall problems with memory bloat; it’s not actually fixing anything. However, it can buy you some time to really dig into your memory problems. You should note that when restarts occur, your app will experience a decrease in throughput as workers are cycled. Due to this, it would be bad to set the restart value to something really low like five minutes.
That’s it for my webserver tricks. Let’s look at how to actually decrease memory use.
Memory at Boot
The easiest way to put your Ruby app on a diet is by removing libraries you’re not using. It’s helpful to see the memory impact each lib has on your memory at boot time. To help with this, I wrote a tool called derailed benchmarks. Add this to your Gemfile:
gem 'derailed'
After running $ bundle install, you can see the memory use of each of your libraries:
$ bundle exec derailed bundle:mem
TOP: 54.1836 MiB
mail: 18.9688 MiB
mime/types: 17.4453 MiB
mail/field: 0.4023 MiB
mail/message: 0.3906 MiB
action_view/view_paths: 0.4453 MiB
action_view/base: 0.4336 MiBIf you see a library using up a large amount of RAM that you’re not using, take it out of your Gemfile. If there’s one that breaks your memory bank but you need it, try upgrading to the latest version to see if there’s been any memory fixes. Two notable and easy fixes are:
- upgrading to mail 2.6.2+
- using mime-types 2.6.1+
In the top of your Gemfile, add:
gem 'mime-types', '~> 2.6.1', require: 'mime/types/columnar'
Pruning your Gemfile helps to decrease your starting memory. You can think of this as the minimum amount of RAM needed to boot your app. Once your app actually starts responding to requests, memory will only go up. To get a better idea of how these two types of memory interact, you can watch my talk that covers how Ruby uses memory.
Fewer Objects at Runtime
After pruning your Gemfile, the next step is to figure out where the bulk of your runtime allocations are coming from. You can use hosted profiling services like Skylight’s memory traces. Alternatively, you can try to reproduce the memory bloat locally with Derailed.
Once you’ve got your app set up to be booted by derailed, then you can see what lines of your application allocate the most objects when you hit an endpoint:
$ bundle exec derailed exec perf:objects
This will use memory_profiler to output a bunch of allocation information. The most interesting section to me is allocated memory by location. This will show line numbers where a large amount of memory is allocated.
While often this will correspond somewhat to allocated objects by location, it’s important to note that not all objects are allocated equally. A multi-level nested hash will take up more space than a short string. It’s better to focus on decreasing allocation rather than decreasing object allocation count.
You’ll likely get a lot of noise from libraries when you run this command:
$ bundle exec derailed exec perf:objects # ... ## allocated memory by location --------------------------------------- 1935548 /Users/richardschneeman/.gem/ruby/2.2.3/gems/actionpack-4.2.3/lib/action_dispatch/journey/formatter.rb:134 896100 /Users/richardschneeman/.gem/ruby/2.2.3/gems/pg-0.16.0/lib/pg/result.rb:10 741488 /Users/richardschneeman/.gem/ruby/2.2.3/gems/activerecord-4.2.3/lib/active_record/result.rb:116 689299 /Users/richardschneeman/.gem/ruby/2.2.3/gems/activesupport-4.2.3/lib/active_support/core_ext/string/output_safety.rb:172 660672 /Users/richardschneeman/.gem/ruby/2.2.3/gems/actionpack-4.2.3/lib/action_dispatch/routing/route_set.rb:782 606384 /Users/richardschneeman/Documents/projects/codetriage/app/views/repos/\_repo.html.slim:1 579384 /Users/richardschneeman/.gem/ruby/2.2.3/gems/activesupport-4.2.3/lib/active\_support/core_ext/string/output_safety.rb:260 532800 /Users/richardschneeman/.gem/ruby/2.2.3/gems/actionpack-4.2.3/lib/action_dispatch/routing/route_set.rb:275 391392 /Users/richardschneeman/.gem/ruby/2.2.3/gems/activerecord-4.2.3/lib/active_record/attribute.rb:5 385920 /Users/richardschneeman/.gem/ruby/2.2.3/gems/temple-0.7.5/lib/temple/utils.rb:47
While the majority of the output here comes from gems like actionpack and pg, you can see that some of it comes from my app running at /Users/richardschneeman/Documents/projects/codetriage. This is an open source app; you can run it locally if you want: CodeTriage.
If you wanted to focus on object allocation inside of your app, you can filter using ALLOW_FILES environment variable.
$ env ALLOW_FILES=codetriage bundle exec derailed exec perf:objects
# ...
## allocated memory by location
------------------------------------
606384 /Users/richardschneeman/Documents/projects/codetriage/app/views/repos/_repo.html.slim:1
377145 /Users/richardschneeman/Documents/projects/codetriage/app/views/layouts/application.html.slim:1
377145 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:1
71040 /Users/richardschneeman/Documents/projects/codetriage/app/views/repos/_repo.html.slim:2
35520 /Users/richardschneeman/Documents/projects/codetriage/app/models/repo.rb:84
19272 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:6
1785 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_head.html.slim:1
1360 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:10
1049 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_footer.html.slim:1This app is already pretty optimized, but even so there’s some micro optimizations we can make. On app/models/repo.rb on line 84, we see this:
def path
"#{user_name}/#{name}"
endHere we’re taking two strings to build up a GitHub path like "schneems/derailed_benchmarks". We don’t need to allocate this new string though since we’re already storing this information in the database in a field called full_name that’s already loaded from the database and allocated. We can optimize this code by changing it to:
def path full_name end
Now when we rerun our benchmark:
allocated memory by location
-----------------------------
606384 /Users/richardschneeman/Documents/projects/codetriage/app/views/repos/_repo.html.slim:1
377145 /Users/richardschneeman/Documents/projects/codetriage/app/views/layouts/application.html.slim:1
377145 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:1
71040 /Users/richardschneeman/Documents/projects/codetriage/app/views/repos/_repo.html.slim:2
# models/repo.rb:84 is not present, because we optimized it
19272 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:6
1785 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_head.html.slim:1
1360 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_repos.html.slim:10
1049 /Users/richardschneeman/Documents/projects/codetriage/app/views/application/_footer.html.slim:1You can see that the models/repo.rb:84 line isn’t present anymore. In this example, we’re saving 35,520 bytes on every page load. If you were looking at object count:
888 /Users/richardschneeman/Documents/projects/codetriage/app/models/repo.rb:84
We’re saving 888 strings from being allocated. In this case, the change is so simple that there’s no downside to committing the optimization. However, not all memory or performance-based changes are so simple. How can you tell when it’s worth it?
I would recommend testing the before and after using benchmark/ips with derailed. By my back-of-the-napkin math, on a MacBook Air with 8gb of RAM and 1.7 GHz of CPU, it takes about 70,000 small string allocations to add up to 1ms of Ruby runtime. Granted this is probably much more power than your production server has if you’re running on a shared or “cloud” computing platform, so you’ll likely see larger savings. When in doubt about a change, always benchmark.
You can repeat running these benchmarks for different endpoints using the PATH_TO_HIT variable.
$ env ALLOW_FILES=codetriage PATH_TO_HIT=/repos bundle exec derailed exec perf:objects
Start with the slowest endpoints in your app and work your way backwards. If you’re not sure what endpoints are slow, you can try out rack mini profiler.
Okay, You May Actually Be Seeing a Memory Leak
I know I said earlier that you don’t have a memory leak, but you might. The key difference between memory bloat and a memory leak is that a leak never levels off. We can abuse this characteristic to expose a memory leak. We’ll hit the same endpoint over and over in a loop and see what happens to the memory. If it levels off, it’s bloat; if it keeps going up forever, it’s a leak.
You can do this by running command:
$ bundle exec derailed exec perf:mem_over_time Booting: production Endpoint: "/" PID: 78675 103.55078125 178.45703125 179.140625 180.3671875 182.1875 182.55859375 # ... 183.65234375 183.26171875 183.62109375
You can increase the number of iterations this tests runs using TEST_COUNT environment variable:
$ env TEST_COUNT=20_000 bundle exec derailed exec perf:mem_over_time
This also creates a newline separated set of values in a file in your tmp/ folder. I like to copy these values and paste them into a Google spreadsheet. Here’s an example:
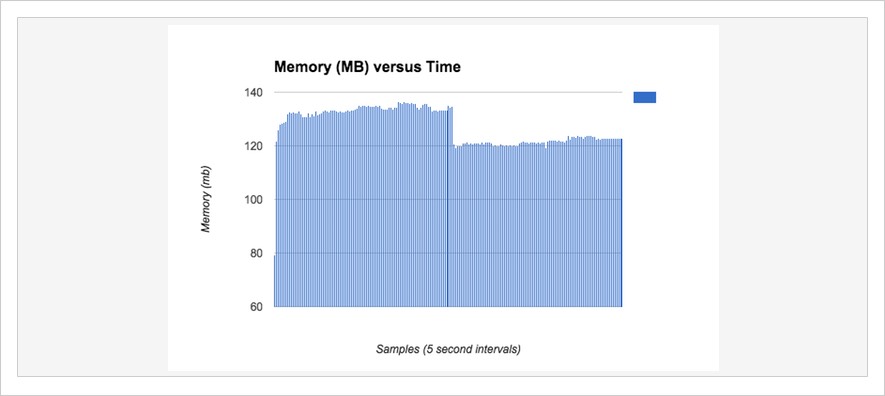
Remember to always label your axis; specifically, don’t forget to include units. Here we can see there’s no leak in CodeTriage on the homepage.
However, if your graph does go up and to the right, what to do? Luckily, removing a memory leak is the same as finding and removing a memory bloat. If your leak takes a long time to become significant, you may need to run the perf:objects command with a higher TEST_COUNT so that the signal of your leak is higher than the noise of normal object generation.
In Conclusion
Even though we use a memory-managed language with a pretty good garbage collector, we can’t completely ignore memory. That’s the bad news. The good news is that normally we can wait until a problem crops up before needing to care too much.
I’m excited that more Ruby programmers are getting interested in memory and performance tuning. As more people speed up their apps, the Ruby community gains more and better institutionalized knowledge. Here’s a list of the tools I mentioned in this article:
If you’ve used all the tricks mentioned here, and you’re still getting memory errors (R14), it might be time to upgrade to a larger dyno with more memory. If you move to a “performance” dyno, you’ll have your own dedicated runtime instance, and you won’t have to worry about “noisy neighbors.”
| Reference: | Debugging a Memory Leak on Heroku from our WCG partner Florian Motlik at the Codeship Blog blog. |
