As I was thinking about this article a few weeks ago, I was excited when I saw that Chris McCord, creator of the Phoenix Framework in Elixir, was on the Elixir Fountain podcast.
One of the things they mentioned on the show was that they were tired of the comparison being made between Rails and Phoenix. The bias of coming from a Rails background may cloud your view of the framework and cause you to think of it as “Rails in Elixir,” rather than something that stands alone and offers new and different ideas from the ones present in Rails.
That being said, I’m making the comparison between Rails and Phoenix as a way to help those who are familiar with Rails understand some of the commonalities between the two frameworks. And also, of course, where they may differ from each other.
Both Rails and Phoenix are web frameworks that share a common goal, that is to help you to be productive as soon as possible. In fact, Elixir’s creator José Valim was a member of the Rails core team, and Chris also comes from a Rails background. So you shouldn’t find it strange to see some of the best parts of Rails resemble what is inside Phoenix.
In this article, we’ll explore not only the typical aspects of an MVC web framework (Models, Views, Controllers), but we’ll also touch on Routing, Assets, and Websockets/Channels.
Getting Your App Up and Running
After you’ve installed the base-level dependencies to be able to create a Rails or Phoenix app (such as Ruby, Elixir, and both of the frameworks), you need to create the app itself. We’ll be building out the beginnings of a Twitter clone in both Rails and Phoenix. I’ve done my best to create them similarly so that it is easy to compare code between them.
Up and running with Rails
The first step in creating a Rails application is to run the command to generate it. This will set up the default folder structure along with all of the files needed to get going.
rails new twitter_rails
Once we’ve done that, we can cd into the directory and tell bundle to install all of the dependencies found inside the Gemfile.
bundle install
The last step is to generate the scaffolding. You’ll notice that the default choice for JavaScript in Rails is to use CoffeeScript while Phoenix decided to go with ES6 instead.
I think Phoenix has made the better decision here, as it seems to be a more modern approach and where things are going. That said, you can definitely write ES6 in Rails too by simply adding a gem.
rails g scaffold User name username:string:unique email:string:unique bio rails db:migrate
Up and running with Phoenix
This will follow a very similar process to the one in Rails. To get started with Phoenix, you’ll run the mix phoenix.new command. This will create the folder structure and files needed for the app. The command I used for the project is below:
mix phoenix.new twitter_phoenix
The next step is to install the dependencies.
You’ll notice that the mix command is a little like bundle in Ruby land, but also a little bit like rake. Another thing to point out is that unless you’re building a pure JSON API (where no assets are needed), you’ll also need to install Node. This is because asset management in Phoenix is handled by a JavaScript library called Brunch, rather than trying to build its own asset pipeline like Rails has done.
Dependencies in Phoenix are found inside of a file at the root of the application called mix.exs inside of the deps method. There is also a package.json file where all of the asset (npm) dependencies are found.
mix deps.get npm install
The next step will be to generate some scaffolding. The command below generates absolutely everything: the controller, model, view, database migration, test files, etc. It’s a very convenient way to get from zero to something that works and quickly. We’ll also run the database migrations right away (later on in this article, we’ll see what they look like).
mix phoenix.gen.html User users name username:unique email:unique bio mix ecto.migrate
Routing
Routing is really the frontline of any web application, where an HTTP request gets sent to a Controller that is prepared to handle it.
Routing in Rails
Routing in Rails happens through a very easy-to-use DSL. Because this is just the beginning of an application, we’ve simply defined two routes. We have one for our users resource, and nested inside, we have the tweets resource.
This allows us to construct complex URLs which look like this: /users/:user_id/tweets in order to see the tweets that belong to a specific user. Both Rails and Phoenix produce RESTful routes when you define them using the resources method like we have below, creating routes for managing the CRUD actions for each resource.
Rails.application.routes.draw do
resources :users do
resources :tweets
end
# Serve websocket cable requests in-process
# mount ActionCable.server => '/cable'
endBy defining routing like this, Rails creates us a series of helper methods to make creating URLs and paths inside the application easier. You can access these either in the views or in the controllers. To see tweets for a specific user, you could use the helper method user_tweets_path(user).
Routing in Phoenix
Routing in Phoenix may at first glance look similar to how it is done in Rails, but the truth is that there is more here than meets the eye. It is a bit longer, yes, but we’ll look at what the different sections are doing.
defmodule TwitterPhoenix.Router do
use TwitterPhoenix.Web, :router
pipeline :browser do
plug :accepts, ["html"]
plug :fetch_session
plug :fetch_flash
plug :protect_from_forgery
plug :put_secure_browser_headers
end
pipeline :api do
plug :accepts, ["json"]
end
scope "/", TwitterPhoenix do
pipe_through :browser
get "/", PageController, :index
resources "/users", UserController do
resources "/tweets", TweetController
end
end
# Other scopes may use custom stacks.
# scope "/api", TwitterPhoenix do
# pipe_through :api
# end
endPlugs and pipelines
Before we get into the details, I wanted to touch on what a plug is.
Plugs plays a major role in the Phoenix framework. Even though they differ, I still think they most closely resemble middleware, such as what is found in Rack-based Ruby frameworks. It is a specification that allows different web servers (such as Cowboy in the Elixir world) to speak a common language regarding the request/response of an HTTP request. Where it differs is that middleware tends to view things as request and response, where plug views things maybe a little more holistically as a connection.
In simplest terms, plugs are a series of methods and modules which pass the connection along and add, modify, or halt it as needed.
In Phoenix, routes are simply plugs, but so are controllers and everything else. Routes and controllers simply provide a different DSL or abstraction for how you relate to plugs.
This brings us to the pipeline code seen in the routing file earlier. What a pipeline does is to define a series of plugs that can be applied to all similar requests. All requests from the browser need such things as session information, protection from forgery, and the fact that they accept html requests. This allows us to say that any request under the / scope will have all of the plugs found in the :browser pipeline applied to them.
In Rails, there is the --api option, which creates a scaled-down version of Rails, devoid of cookies, sessions, form forgery protection, etc. This isn’t needed in Phoenix because we can choose which pipeline the request should flow through, and therefore which set of functionality is used.
Method signature pattern matching
Another interesting thing about routing in Phoenix is that it is actually a series of macros which generate methods that have the same name but with different signatures. Elixir is a language which has pattern matching. This allows us to define the same method twice but with different signatures, and the Erlang VM, Beam (upon which Elixir is built), will efficiently choose the correct one to call.
For an example of how pattern matching works, let’s look at the simple example below. There are two methods with the same name, hello, but have a different method signature. Namely, one expects an argument and the other doesn’t. This can also carry the name polymorphism.
defmodule Sample do
def hello(name), do: "Hello, #{name}"
def hello, do: "Hello, nameless"
end
IO.puts Sample.hello("Leigh") # Hello, Leigh
IO.puts Sample.hello # Hello, namelessOr to bring the example a little closer to routing, we have two route methods below, which both accept a single argument. But this time, Elixir matches which method to call based on the shape of the data itself, namely whether the strings match the same pattern or not. Hence the name “pattern matching.”
defmodule Routing do
def route("/"), do: "Home"
def route("/users"), do: "Users"
end
IO.puts Routing.route("/") # HomeCode that is written like this can tell a more straight-forward story. Even though this could be accomplished by if statements or other control-flow logic, in this case, each method has a single purpose for specific input.
App Architecture
Microservices are hot topics these days. I wrote an article on architecting Rails apps as microservices, which focused on communicating between smaller, single-purpose applications through either HTTP requests (and JSON) or asynchronously through some sort of queue. While there are arguments back and forth between microservices and the so-called “majestic monolith,” this isn’t really something you need to think about when working with the Phoenix framework.
Elixir is built upon the Erlang programming language, a language which is highly concurrent by its very nature. One of the features of Erlang is something called OTP (Open Telecom Protocol), originally built for managing large, distributed telecom systems.
What OTP gives us at a very high level is the ability to have an application supervision tree. Each parent will watch over child applications and can be configured with what to do if there is a problem with the applications that it is supervising.
Our Phoenix app itself is just another OTP application which can live within the supervision tree of a larger application, which may involve other “apps.” This would generally be where you start to think of creating microservices. But it’s baked in to the language itself.
Inside of the mix.exs file there is an application method that defines our TwitterPhoenix app along with the other applications needed for ours to run. These are all lightweight processes which can communicate back and forth between each other, all managed by the Erlang VM, Beam.
def application do
[mod: {TwitterPhoenix, []},
applications: [:phoenix, :phoenix_html, :cowboy, :logger, :gettext,
:phoenix_ecto, :postgrex]]
endOne cool feature of this setup is that it comes with a built-in visualizer called observer that lets us peek into each of the processes to view their state and where they fit in the larger OTP supervision tree. It can be started from within iex (the Elixir REPL) with the command :observer.start().
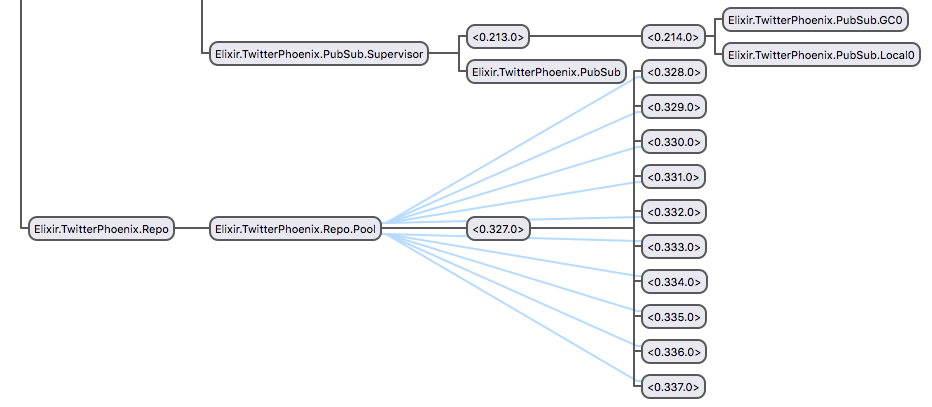
We’ll leave it at a high level here. For more information, you can refer to the Elixir docs on supervisors and applications along with Programming Phoenix by Chris McCord, Bruce Tate, and José Valim, which has a chapter on Mix and OTP that goes into greater detail.
Conclusion
This ends Part I of the comparison between Rails and Phoenix. In Part II, we will begin with the Model and proceed through the Controller and the View. I hope you’ve started to see that, while similar, the ideas and patterns found in each of the frameworks do differ, all while accomplishing the familiar goal of receiving an HTTP request and building the appropriate response.
| Reference: | Comparing Rails and Phoenix: Part I from our WCG partner Florian Motlik at the Codeship Blog blog. |
