Building complex software projects is almost always an iterative process. We rarely get to spend months designing and writing a complete project before releasing something to our users. This process of incremental software development can be accomplished in many ways, but one of my favorite strategies has been through microservices.
I won’t cover microservices in depth as they’ve been covered on this blog before. Instead, I’ll focus on:
- An overview of incremental software development and how it fits into the ecosystem of development buzzwords.
- Examples of how I’ve used PHP microservices to incrementally develop software projects.
- Some takeaways that I have picked up during these projects.
What Is Incremental Software Development?
First, there isn’t an “official” definition for incremental software development. It’s basically just a blanket term used to describe the observation that most modern software is not built wholesale and then left alone. Software evolves as the business around it changes and as new customers are discovered. A convenient term for this phenomenon is, therefore, incremental software development, but this idea is also present in other product development systems.
How iteration happens with physical products

First, we come up with an idea — in the case of this image, something to sit on. Next, we want to validate that someone will pay for the idea and that the idea is feasible, so we’ll put together a minimum viable product (MVP). If that goes well, we will release new versions of the product based on our learnings about what customers want.
In this example, each version is a complete rebuild of the initial product. Very little of what we used for the previous build will work for the next one, but we did learn a little more about our customer’s needs each time, so our product iterations should improve.
This process of iteration and validation is how we build software too, but the model above doesn’t accurately capture the way in which we can break our software into components and reuse them.
How product iteration happens in software development
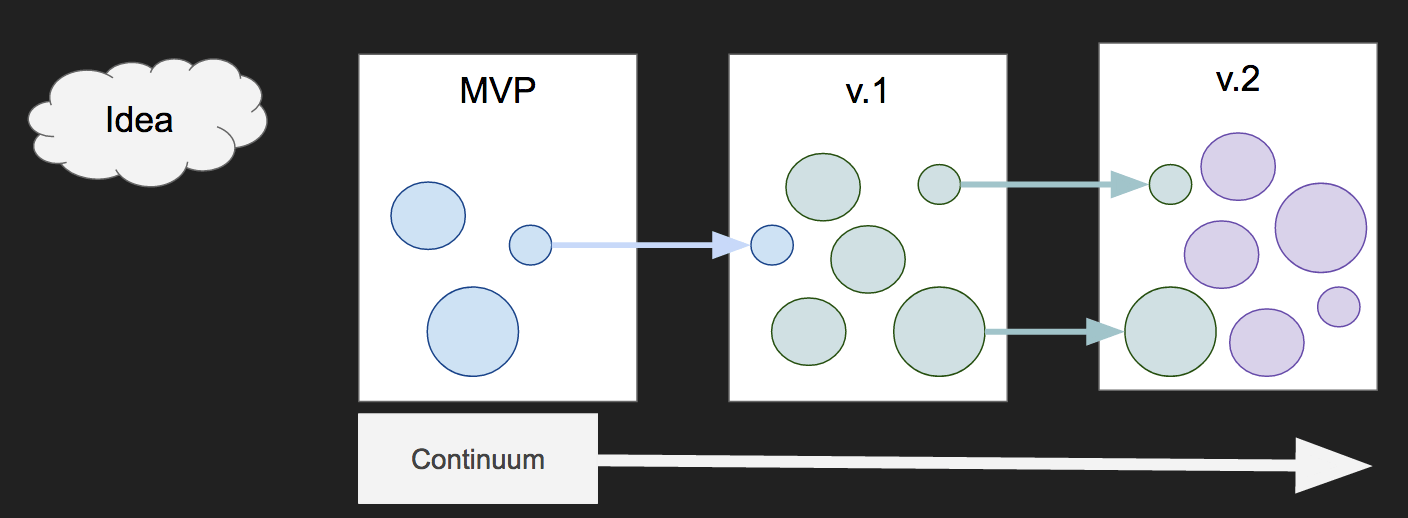
Each major version of our product is not entirely encapsulated. We develop software in a continuum: applications (or modules, or microservices depending on your choice of architecture) carry over from one iteration to the next. This is not to say that some companies don’t do greenfield rebuilds, but many would argue that’s not a good idea, especially when the product is large and the business needs it to continue working.
Incremental software development is all about building evolvable software. It is encompassed in ideas like Lean Product Development, Extreme Programming, and Agile Development. In all of these methodologies, the goal is to build the best product possible based on the resources and knowledge available at the time. “Best” can mean different things depending on the needs of the business, but if you buy into the hypothesis that these needs will change over time, it benefits you to think about building software that can be incrementally improved.
Now that you know what I mean when I use the term incremental software development, let’s look at some examples of projects that have used the approach with PHP microservices.
Example 1: Packback’s Pivot
When Packback started, the founders’ vision was to save students money by offering digital textbook rentals on a daily basis. The challenge was that publishers had to grant us rights to distribute their books using this new pricing model, but they wouldn’t grant us mass distribution rights without knowing that we could reach thousands of college students.
We were stuck in a classic chicken and egg dilemma. We couldn’t get publishers until we could get more college students renting textbooks and we couldn’t get college students to rent textbooks if we didn’t have distribution rights to rent them out.
So, we decided to circumvent the publishers and build a product that college students would use whether we had textbooks to rent or not.
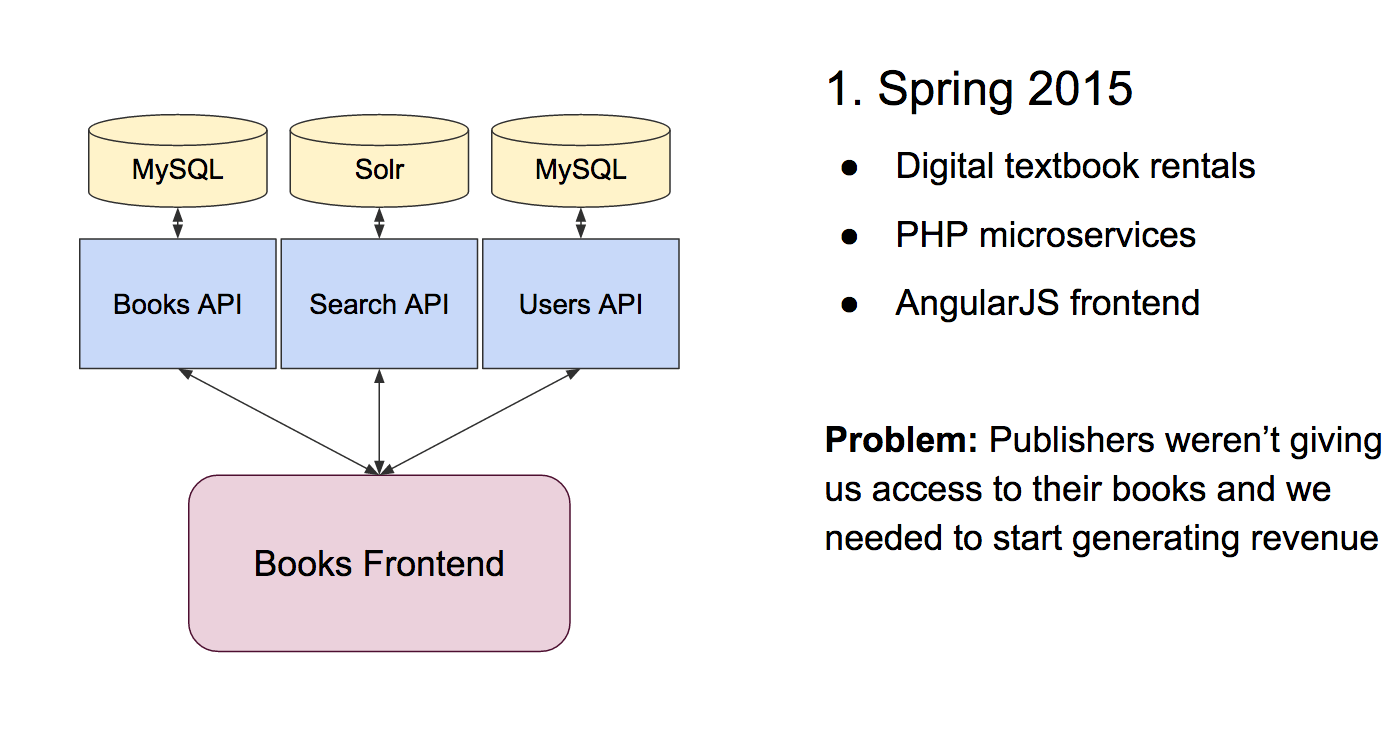
Before we started work on the new product, our software product was a pretty standard textbook rental platform built using PHP microservices in Laravel. Users could sign up, search for books, compare prices (used versus new versus rental), and check out when they found their textbooks. We had offloaded the e-reader experience to a third party, which kept the platform pretty lean.
Packback’s microservice architecture for textbook rentals
When we decided that we needed some way to attract students to our platform while we negotiated with publishers, one of our founders wanted to try building a question-and-answer platform.
His vision was that professors and students would use it to discuss the class, and Packback could advertise or bundle its textbook rentals right there in the platform. So, one of our founders and a couple interns put together the MVP for this Q&A product without any developer resources.
Packback’s MVP Q&A platform

This first version of the product used a platform called Answerbase, which allowed us to whitelabel their Quora-like Q&A product. We tracked users and generated professor reports (the professors basically wanted to know how much their students were using the discussion platform) using Google Drive and MailChimp. With around 100 students to track, this was pretty easy to manually manage, and because we hadn’t diverted any engineering time, it was a very low-cost test.
This MVP proved that professors and students would use a better discussion platform, but we were still struggling to close deals with publishers. I think textbooks are an industry that is ripe for change, but as we found out, most publishers are still not ready to make pricing leaps.
Paying for the platform
We wanted to see if there was a possibility that we could charge schools or students directly for the use of our Q&A platform. We offered “Packback Answers” as a bundle with the textbook to a few more professors and started automating bits of our MVP using Zapier and some custom scripts:
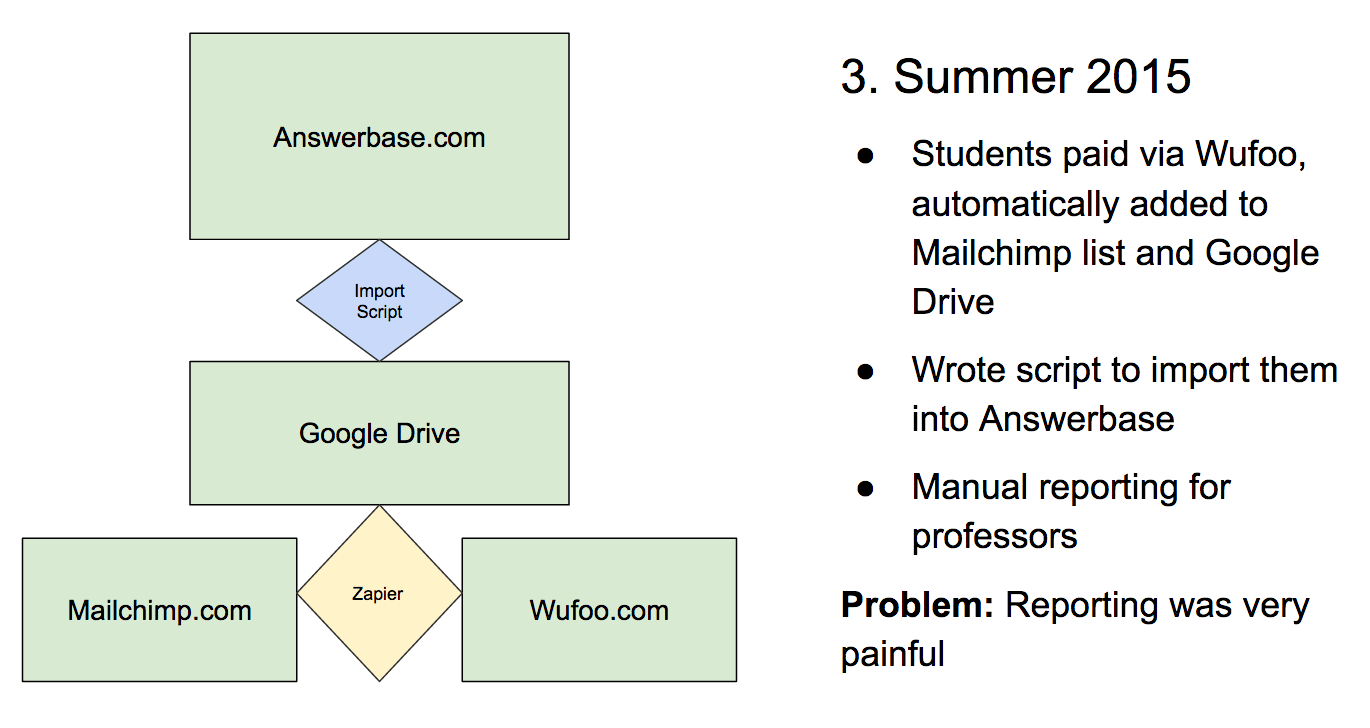
This let us test the theory that students would pay for access to a platform like this as part of their course fees, and we could send them weekly marketing emails to remind them to post. Engagement rose, professors started using our Q&A platform as part of the class grade, and we started to push more engineering resources into the project.
Addressing the pain-points with automation
Setting up new communities and onboarding students was a challenge. Answerbase started to have issues handling our intermittent traffic spikes, and the process of counting posts every week to report back to professors was basically a full-time job. Zapier was fine, but we were struggling to use spreadsheets as a permanent data store for thousands of students.
Around this time, we began to explore and spec a wholesale rebuild of the product based on what did and didn’t work well. Simultaneously, we had to address some of the major issues in the existing Answerbase-backed platform to allow it to scale to the thousands of users we now had:
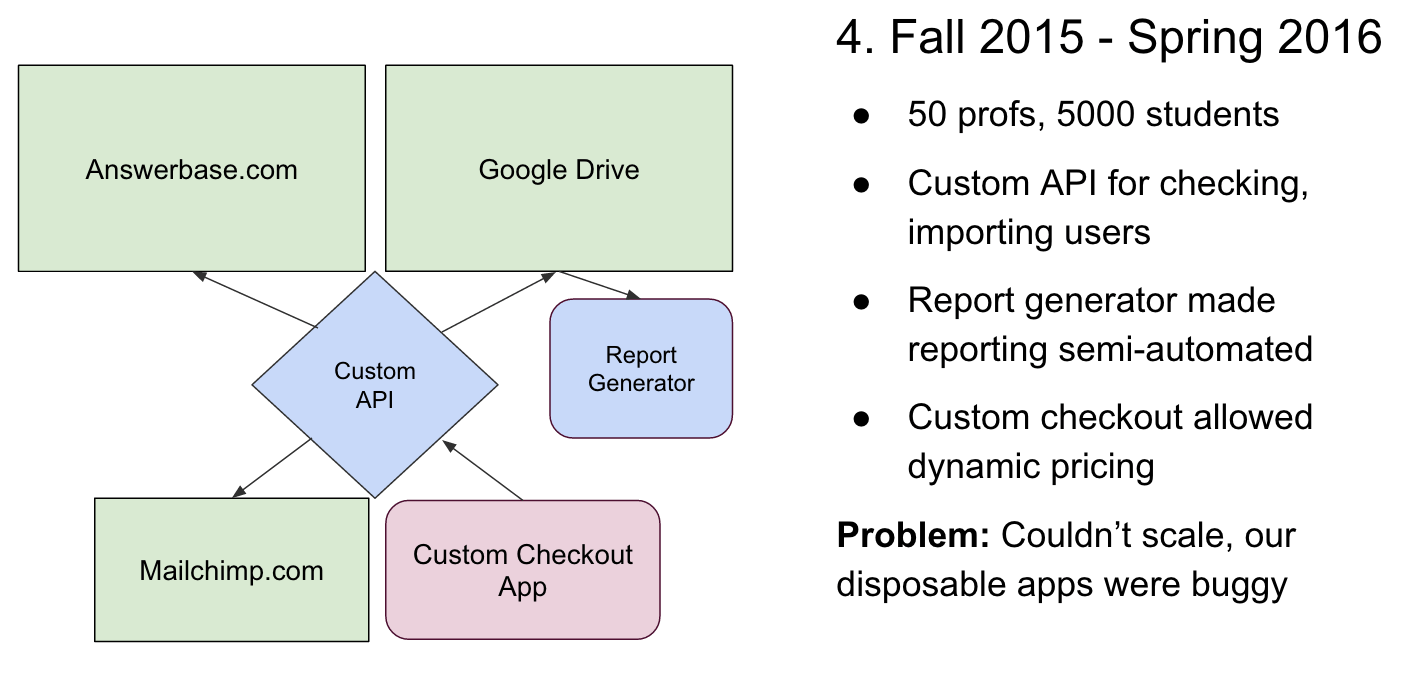
We built some sacrificial architecture to alleviate the pains of checking out on Wufoo and generating reports for professors. This custom API and custom checkout app were simple and not well-constructed, but they did get us through a couple more quarters while we worked on the rebuild.
The engineering team had been completely diverted from Packback’s book rental platform, and we were basically just addressing critical bugs at that point. It had become clear that the Q&A platform was viable, students would pay, and there was room in the market to scale. We had a few sales people working with professors and a full-time customer success representative to onboard them. Thousands of students were now using Packback to discuss their classes and textbooks.
Launching the rebuild
It was an exciting time at Packback because we finally had some traction, but a bit nerve-racking as well. The engineering team had to release a rebuild that would immediately address the scale of users and the scope of features that the existing product did.
Eight months after we started the rebuild, we were able to release it to a few new classes in the summer of 2016:
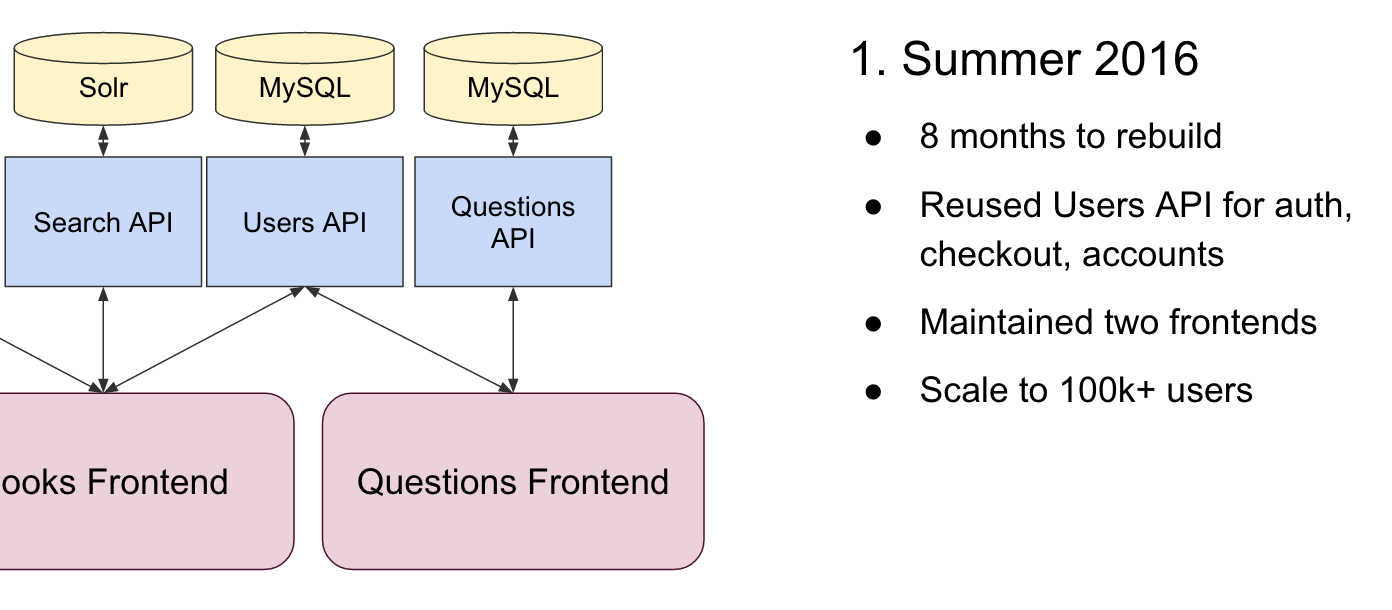
We were not able to reuse much from the first version of the Q&A product, but we were able to reuse our Users API from the textbook rental platform we had finished the previous year. The Users microservice handled authorization, account creation, and transactions, so it dovetailed nicely into our needs for the new product (now named Packback Questions).
Example 2: The Graide Network’s Escape from Legacy Code
I’ve written about this process a couple times before (here and here), but this overview will include visuals as well.
Some background
The Graide Network is a two-sided marketplace where elementary-school teachers can upload completed student assignments, and we match those assignments up with “Graiders” (mostly college students studying to be teachers) who grade them for a fee. The business had done a really good job making things work with an unreliable platform before I joined, and they were able to fall back to Excel sheets and email when the software wasn’t working right.
When I started working at The Graide Network, the platform was a monolithic CodeIgniter application running on an outdated version of PHP:
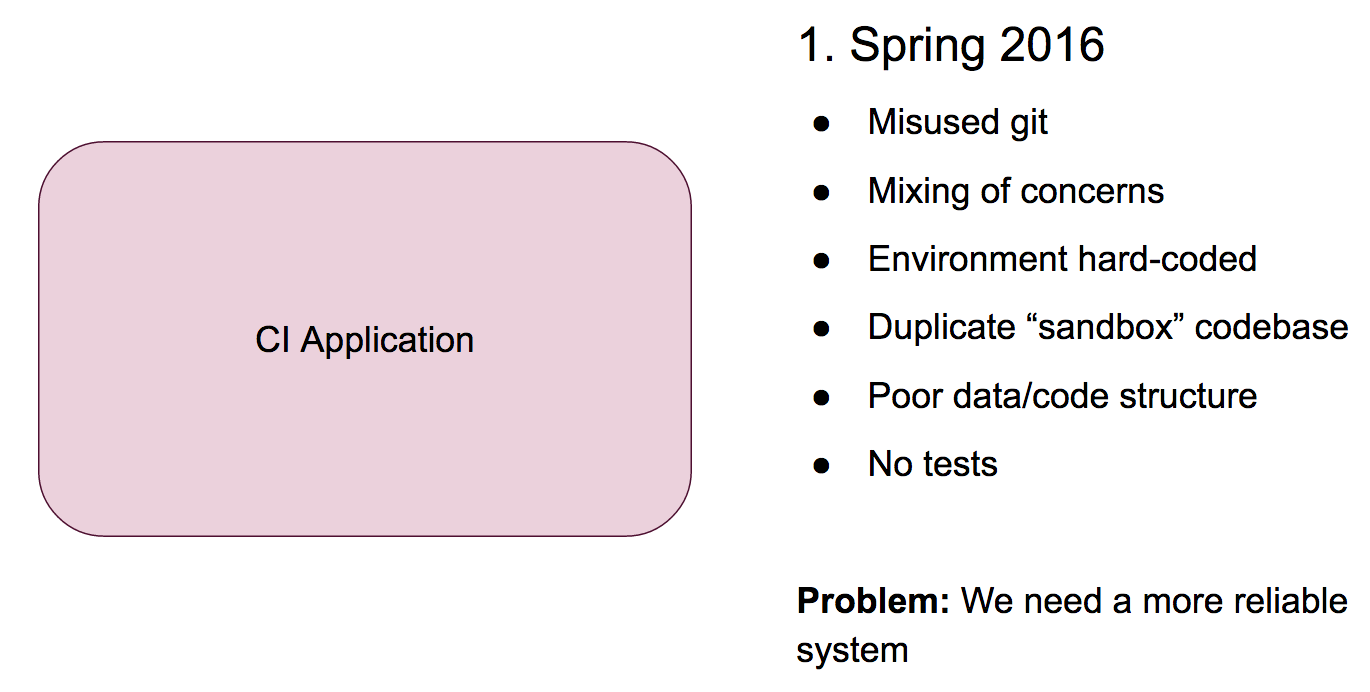
Git was being misused (the previous developer had committed only once), there were raw SQL queries written all over the place, environmental variables were hard-coded, there was an entire duplicate codebase checked into the repository (called “sandbox,” so I assume they used it as a dev environment), and there weren’t any tests. Needless to say, our reliability issues stemmed from this poorly designed piece of software.
Taming the beast
Some improvements were obvious, but others had to be discovered by digging in. I quickly realized that updates to marketing materials, the blog, and signup pages were going to be very cumbersome. As a result, we moved all of those functions into a simple Squarespace site that the business team could modify.
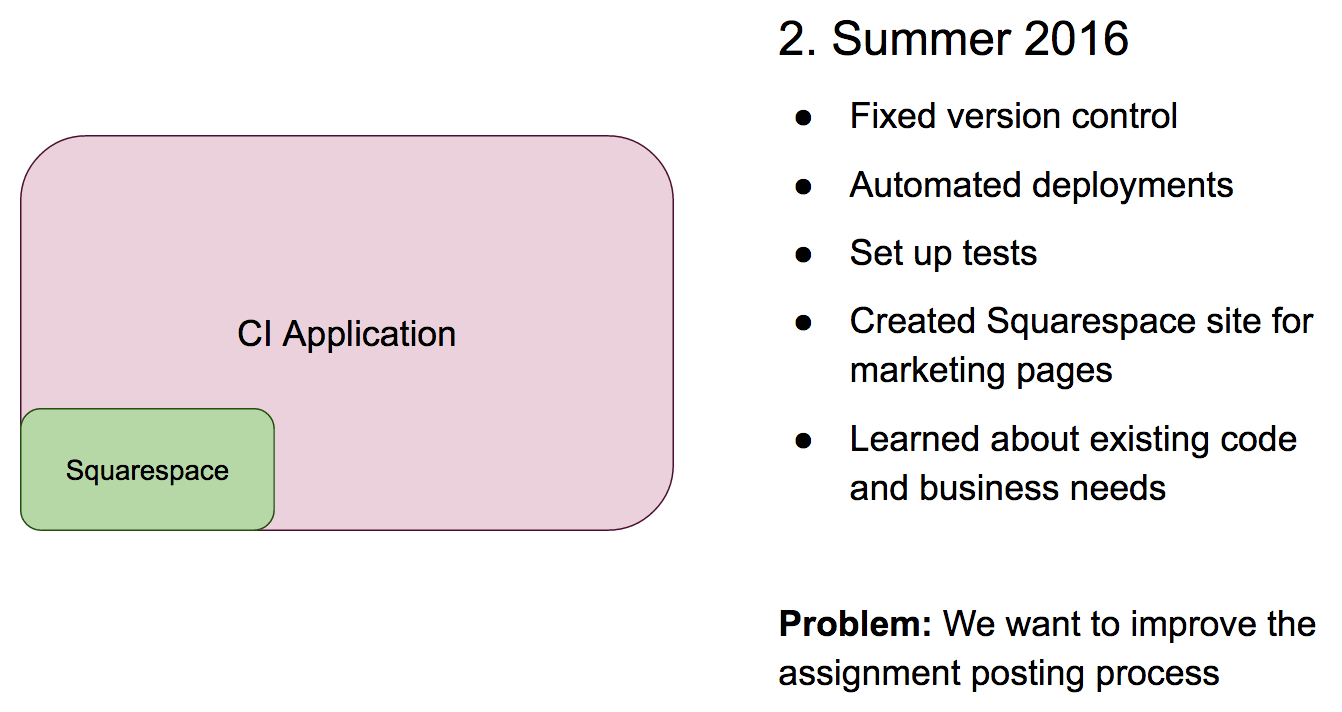
While setting up some basic tests and cleaning up the repository, we learned a lot about the strengths and weaknesses of the codebase. This allowed us to prioritize the technical debt we needed to settle in order to move forward with new features.
At this point, it was tempting to consider a complete rebuild.
Unfortunately, we had only two developers and less than three months to get ready for the next semester. My experience at Packback had taught me that starting a rebuild at this point would be extremely risky. However, I felt confident that if we focused on the parts of the application that were the most brittle, we could live with the rest of it for a while.
Replacing broken data models
The business team’s biggest feature request was to change the way that Assignments and Courses were created. By this point, we had been in the code enough to know that changing the interface would be impossible with the current data structure. So we started the first in a series of surgical processes to remove the legacy data tables and replace them with Laravel PHP microservices.
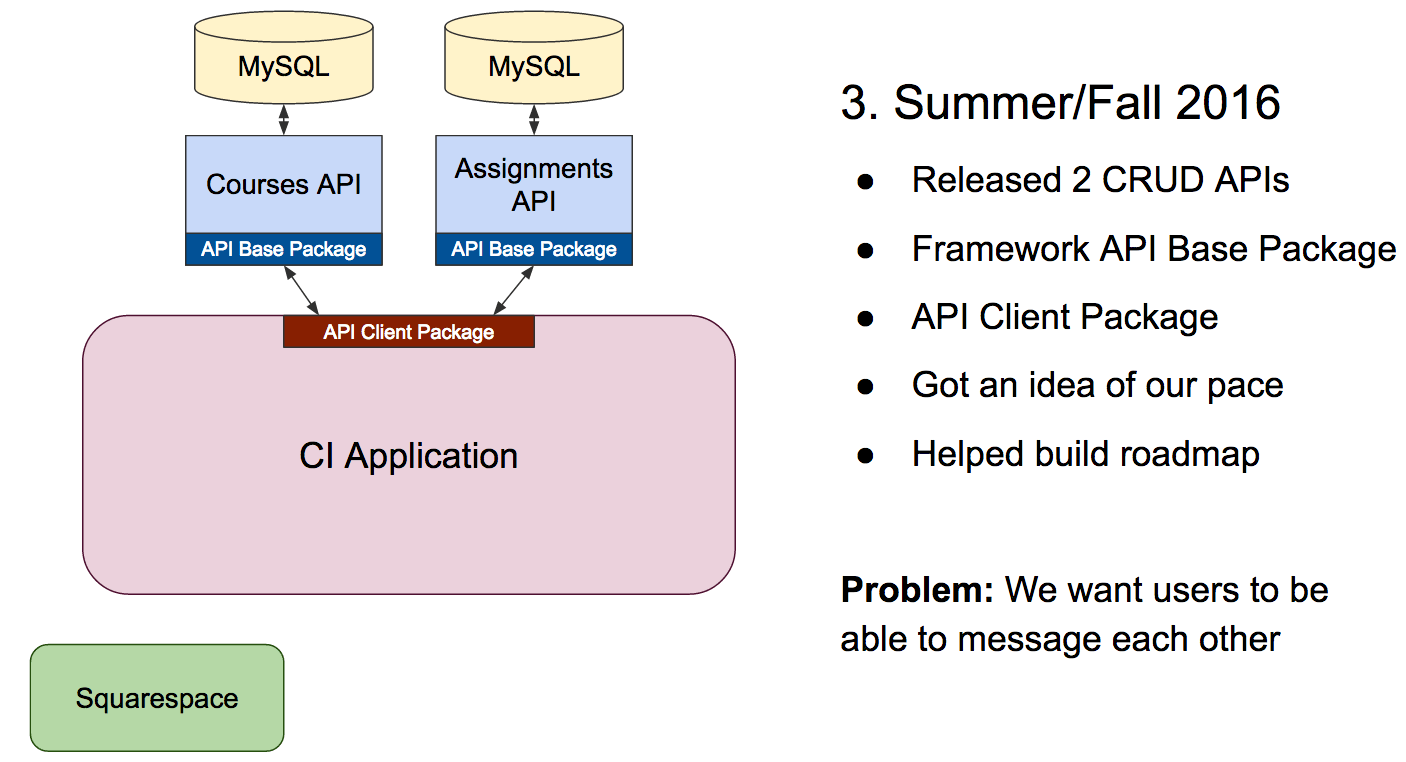
Initially, the two microservices we created pretty much just handled CRUD operations, and we left most of the business logic in the legacy CodeIgniter application. We built a couple Composer packages to help us set up new microservices more quickly and standardize our data objects between the services. This gave us a pattern for the work we would do over the next few months, and it allowed us to hit our fall target with improved data models and interfaces for Teachers and Graiders.
There were still a lot of problems in the code that we hadn’t addressed, and we had a ton of ideas for new features to implement. Fortunately, our quality was improving, and we were getting more confident about making changes to the product.
Continuing the process
The next features we worked on were messaging and user profiles. Both of these features were pushed into a new Users microservice, and we made the decision to start putting as much business logic back into the APIs as we could:
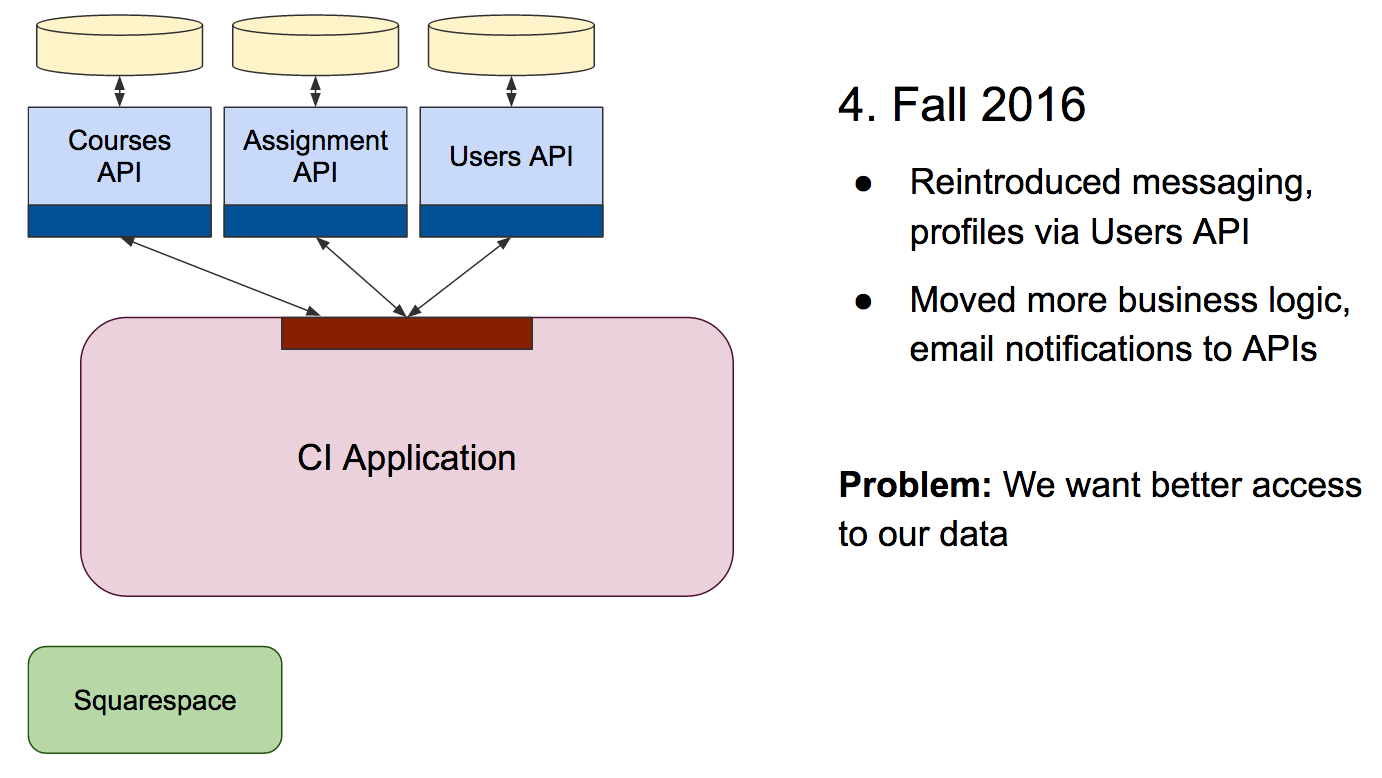
Normally, it’s a good idea to keep microservices lean. However, in this case the technical risk of having the CodeIgniter application do more of the work outweighed the desire to keep our APIs smaller.
Next, the business team wanted to more easily access data from the platform. We built a couple simple admin interfaces, but eventually figured out that what the team really needed was to export data to CSV files. This allowed us to download assignment data and analyze it in Excel rather than having us build every possible sorting and filtering feature into the platform.
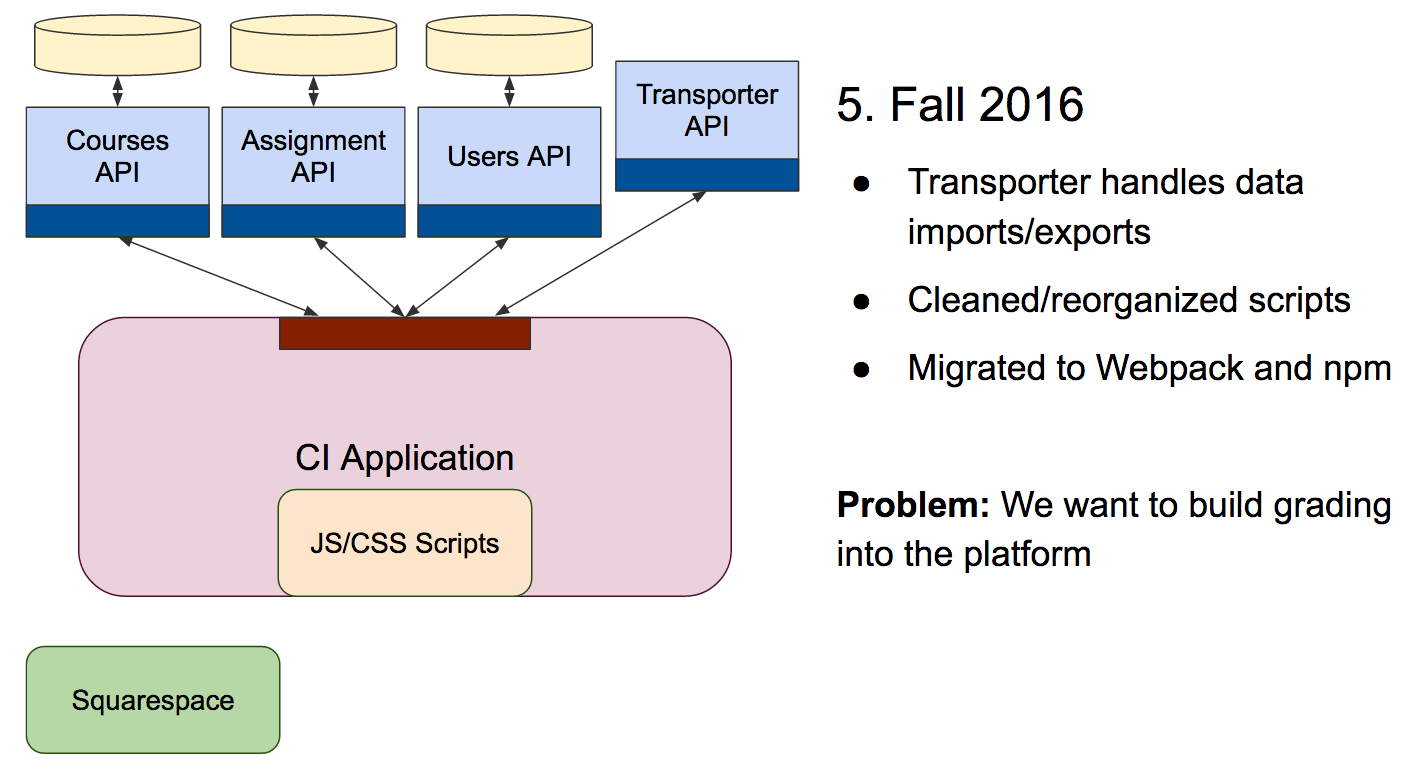
We also started migrating to Webpack. The frontend code was a mess: Scripts were hotloaded all over the place, styles were inlined, and there were dozens of unused or redundant CSS files.
Finding a frontend opportunity
As we removed responsibilities from the legacy CI app and moved it down the stack into the APIs, we were looking for a justifiable need to start the migration to a new JavaScript frontend. We were provided an opportunity in late 2016 when we decided it was time to move the grading process into the application.
Grading assignments was currently done in Excel or Google sheets. Graiders would download the student work, open a grading template file on their computers, and enter grades one-by-one as they went through the assignment. Grading in the platform would allow Graiders to do their work more quickly and give teachers and principals better access to data on their students’ work.
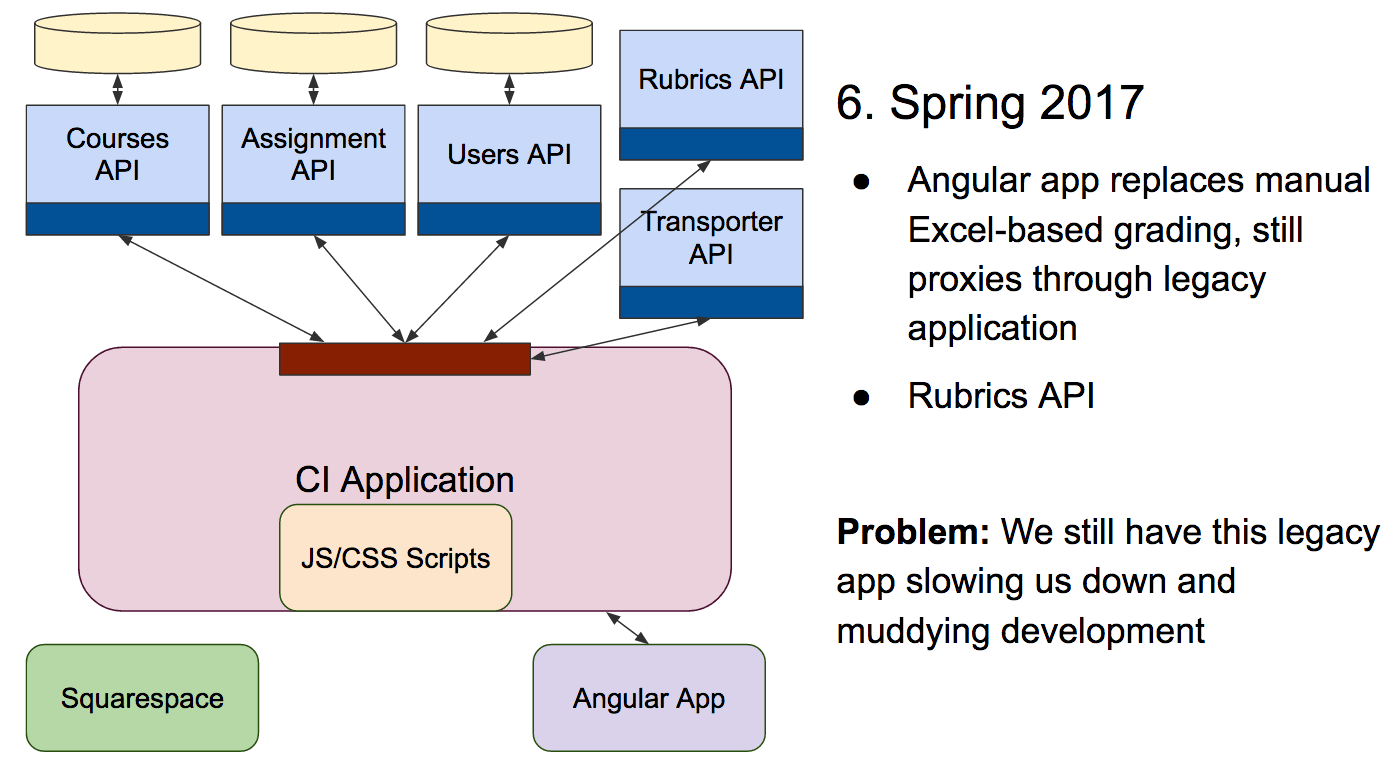
In-app grading was a perfect opportunity to start migrating to Angular, which allows us to better organize our JavaScript and build an application that responds more quickly to real-time interaction. Currently, the Angular app is just used for in-app grading, but eventually it will replace the whole CodeIgniter frontend.
A vision of the future
Finally, I’ll leave you with the goal of where we’re heading at the Graide Network:
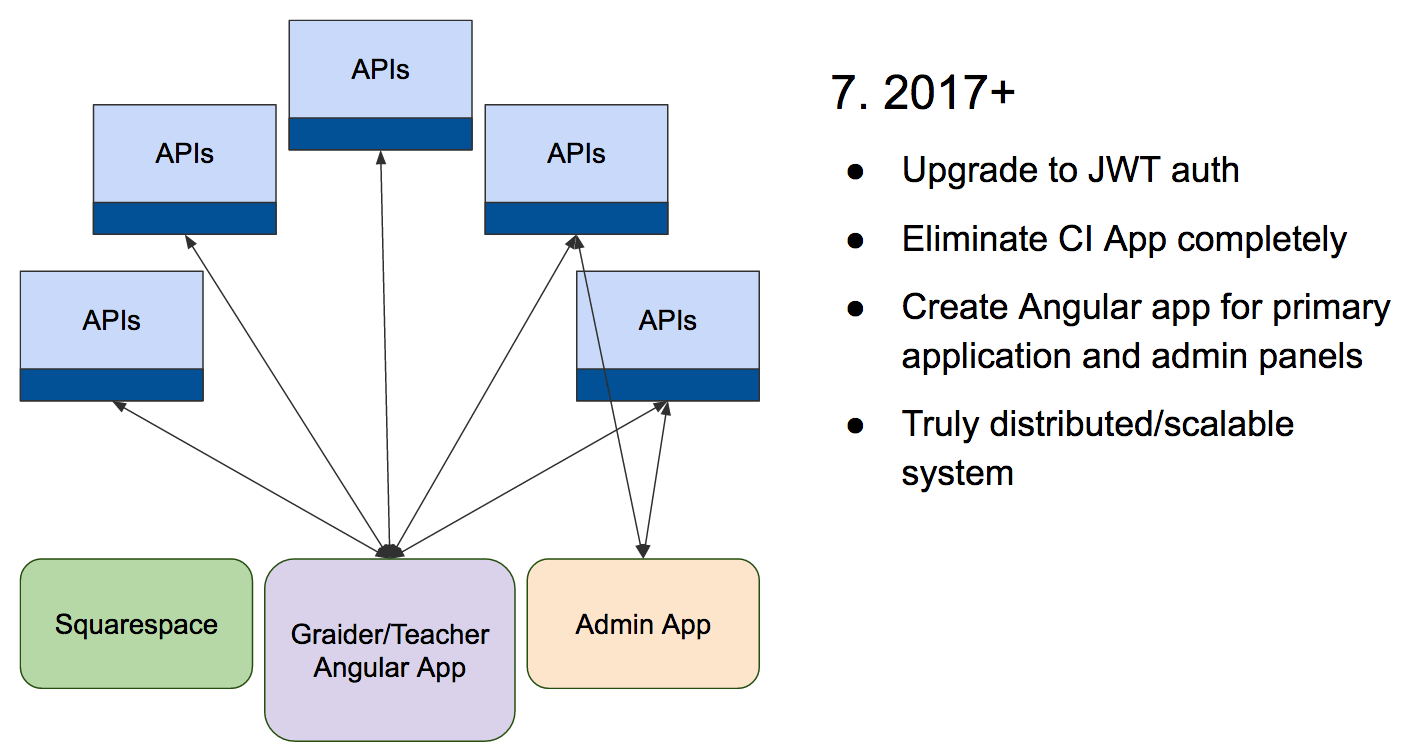
Eventually the CodeIgniter application will be replaced by a stateless authentication system, an Angular frontend, and many PHP microservices. This setup will give us the ability to continually adjust our application’s direction, scale services independently, and migrate data quickly if we ever need to do so.
Lessons Learned
Leading these projects over the past three years has taught me a lot about incremental software development, but here are some of the most apparent takeaways:
- My biggest mistake in leading the Packback Q&A project was not building reusable components during the first version of the Q&A platform. The temporary apps we built to handle checkout and reporting were buggy and distracted the team from our next iteration of the product.
- Disposable architecture is always a bit of a technical risk, but if I had to build something that I knew I would throw away again, I’d decrease the number of features and increase testing and reliability.
- Using third-party applications to supplement or validate your idea can work really well. It means your engineers just have to write “glue” code which is much less risky than starting from the ground up. Microservices help here. If you can’t find a third-party service that does what you need, you can limit yourself to a microservice that fills in whatever gaps your architecture has.
- Greenfield rebuilds take longer than you think. You will have to maintain two products. Be ready for this.
- When making sweeping changes to an application, give yourself the ability to roll back to a previous version quickly. We built feature toggles in the early stages of rebuilding at the Graide Network to help mitigate risk.
- Microservices can help compartmentalize code, but they come with their own challenges. You’ll need to build infrastructure to handle queues and integrate data; you’ll need to automate your builds and deployments (Codeship is a great resource for this); you’ll want to figure out a testing strategy.
If you’re interested in hearing more about this topic or you’ve got something to add, you can find me on Twitter.
| Reference: | Incremental Software Development with PHP Microservices from our WCG partner Karl Hughes at the Codeship Blog blog. |
