Caching is a way to store and reuse the same data multiple times. By data, I mean anything like images, CSS files, JSON, etc. Caching will help you serve more requests per second and save on precious resources like network bandwidth and CPU load.
What are some of the benefits and challenges that come with caching? What are the most important things you should know about every caching layer? In this post, I will do my best to answer these questions for you!
Caching Challenges
Caching comes with its own set of challenges you have to deal with. For example, what strategy are you going to use to decide when the cached data is stale? There are two main strategies:
- Expire a cached entry after a certain amount of time has passed.
- Expire a cached entry after the original resource has changed.
The second option can be implemented by some event that changes the data and then triggers the cache refresh. Another way to implement this is by doing what Rails does by default, and that’s to fingerprint (using a cryptographic hash) the file content.
It looks like this:
application-58d13b8475db67dfa81ae346b0ae67e9.css
When the file changes, the fingerprint also changes with it, which will trigger the browser to request what looks like a new file.
Now that you are familiar with the main challenge imposed by caching, let’s review some of the most common caching methods, including:
- Browser caching
- Key-value caching
- Application caching
Browser Caching
Browser caching is probably the most common type of caching that you will find in the wild. It’s a collaboration between the browser and the web server, used to speed up the loading time of repeated visits to the same site.
Keep in mind that browser caching is an extensive topic, spanning multiple specification documents (rfc7234, rfc7232), so I will not cover every detail here.
Let me explain how browser caching works: When you load a site for the first time, your cache for that site is empty, so you have to request every resource (CSS, JS, images, etc.). Then, when you reload that page, a few things can happen in terms of caching:
- If the
Expiresheader is set to a date in the future, the resource will be loaded from the cache and no server request will be made. - If there is no
Expiresheader or if it has a date in the past, the resource is requested again. The browser will send any other caching headers back with the request (likeIf-None-MatchandIf-Modified-Since).
Then if the server determines (using one of these caching headers) that the resource hasn’t changed, it will return a response with HTTP code 304 and no data. This saves the server some work and some bandwidth. When a browser receives the 304 ‘Not modified’ code, it will load the resource from the cache.
Browser caching in action
Let’s analyze some example interactions using Chrome’s network panel (you can open it using F12 & clicking on ‘Network’). If you want to follow along make sure to clear your browser’s cache first!
Here is the initial request for jquery.min.js:
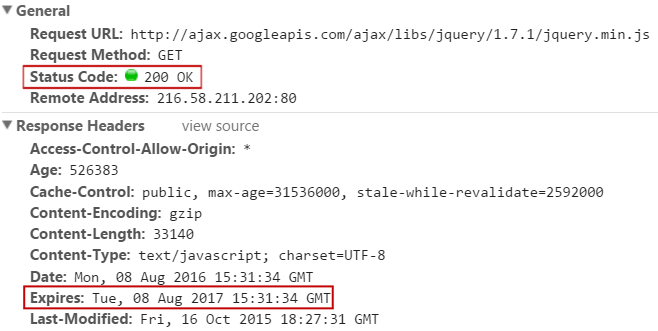
Since this is the first request for this file, we get a 200 OK response with the file contents.
Notice the Expires header, which tells the browser that it doesn’t need to request this file again until August, 8 2017. In this response, we can see another two caching-related headers: Last-modified and Cache-Control.
Google recommends that you set your Expires header to at least one week in the future with a maximum of one year.
Now let’s reload this page by pressing F5 and see what happens…
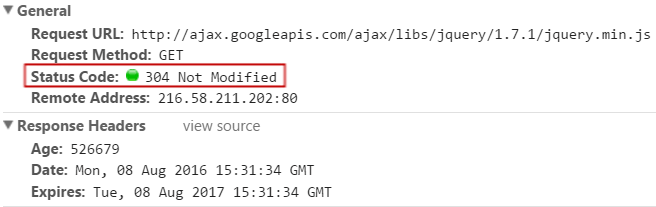
There are a couple of things going on here. To start with, we didn’t expect the browser to request this resource again, since the Expires date is set in the future.
Also we are getting a 304 code, because of the If-Modified-Since header that our browser sent with the request. So why didn’t we get the expected behavior? Is the Expires header useless?
Well, the thing is that most browsers will “re-validate” all possible resources when you press F5. This probably happens because, when you press F5, you are looking for the page to update, so it wouldn’t make sense to reload everything from the cache.
But let’s see what happens if you use a bookmark or type the URL and press ‘Enter’ (tip: if you press F6, Chrome will focus the address bar without deleting the current URL).

This time, you can see that Chrome says 200 (from cache) in the response code of the network panel. This means that the Expires headers is doing its job!
The Etag Caching Header
We have already discussed the Expires header and the time-stamp-based validation (If-modified-since) header. But what we haven’t covered is the Etag header. This serves the same purpose as the If-modified-since header, but instead of a time-stamp, it uses a hash-based approach.
Here is an example so you can see what I mean:
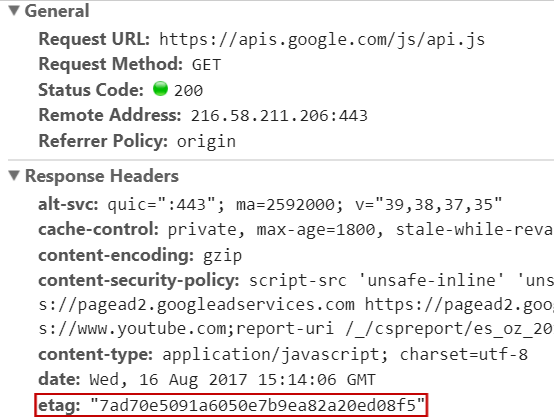
The Etag header is formed using multiple data points. For example, in the Apache web server, the default Etag is constructed from:
- The file size
- The i-node number
- The last time the file was modified
An i-node represents a file or directory in an Unix file system. This solves the expiration problem because whenever one of these parameters changes, the Etag hash will not match and the resource will be considered stale.
For more details on the Etag header, check out this Wikipedia article.
Application-Level Caching
Let’s explore another caching type: application-level caching, also known as memoization. This type of caching is useful when your program uses a method that is very slow, like reading a file and extracting some data from it or requesting data from an API.
If we are going to use the data returned by this slow method multiple times, it doesn’t make sense to have to request it from the original source every single time. One solution is to store the results of this slow method in an instance variable, then return these stored results on subsequent calls to this method.
Let’s take a look at a code example:
def slow_method @results = @results || get_data_from_api end def get_data_from_api sleep(3) 345 end p slow_method p slow_method p slow_method
If you run this code, you will notice that it takes about three seconds (which simulates the slow method) to print the method’s result for the first time. But all the following calls to slow_method are going to be very fast, because there is no work to do.
This feat is accomplished by this code:
@results = @results || get_data_from_api
What this is saying is:
“If
@resultsalready exists, then keep it the way it is and return the stored result. If it doesn’t exist, then make the slow API call to get the data we need and store it on@results.”
A shortcut that is often seen in Ruby code is this:
@results ||= get_data_from_api
Don’t let the weird ||= symbol confuse you; this code does the same as the last example.
Actually,
x ||= ymeans exactlyx || (x = y), but that’s just a small detail.
One of the potential downsides of memoization is that you will lose your cached data whenever you restart your application. And if you are using multiple applications’ servers, you won’t be able to share this cached data.
Key-Value Data Caching
On the last section, you learned how you can use memoization to temporarily store the results of a slow method. You can take this a step further with dedicated ‘key-value’ databases like memcache or Redis.
One benefit of using something like Redis is that your data will be able to persist through user requests and application reboots. The main downside is that you have to introduce another dependency to your application and another thing to keep an eye on.
It’s really easy to use Redis in your Ruby applications; all you need to do is install the server and its corresponding Ruby gem.
Redis versus memcache: Both can be used for caching, but Redis offers many more features, like being able to persist data to disk. Here is a Stack Overflow answer if you want to learn more.
Let’s take a look at a Redis code example:
require 'redis'
redis = Redis.new(host: "127.0.0.1", port: 6380, db: 15)
redis.set("user:1:last-login", Time.now)
# => "OK"
redis.get("user:1:last-login")
# => "2017-08-15 05:19:10 +0200"You can work with Redis with just two methods: get & set. You can think of this as a remote hash table. In addition to caching, Redis is also very convenient for things like counters or some other kind of shared temporary data (like user sessions).
Summary
Now you should have a better understanding of the different types of caching available to you.
But which ones should you use? Well, for starters, browser caching is a good baseline and it doesn’t require you to write any extra code. A properly configured web server should take care of this.
From there, you should identify what some of the “hot spots” are for your application using profiling tools (like rack-mini-profiler) and implement another caching layer if it helps make your app faster without major downsides.
If you enjoyed this article, don’t forget to share it on your favorite social networks and to subscribe to our newsletter!
| Published on Web Code Geeks with permission by Jesus Castello, partner at our WCG program. See the original article here: An Overview of Caching Methods Opinions expressed by Web Code Geeks contributors are their own. |
