This is the third part of a three-part series on working with DynamoDB. The previous article, Querying and Pagination with DynamoDB, focuses on different ways you can query in DynamoDB, when to choose which operation, the importance of choosing the right indexes for query flexibility, and the proper way to handle errors and pagination.
As discussed in the first article, Working with DynamoDB, the reason I chose to work with DynamoDB was primarily because of its ability to handle massive data with single-digit millisecond latency. Scaling, throughput, architecture, hardware provisioning is all handled by DynamoDB.
While it all sounds well and good to ignore all the complexities involved in the process, it is fascinating to understand the parts that you can control to make better use of DynamoDB.
This article focuses on how DynamoDB handles partitioning and what effects it can have on performance.
What Are Partitions?
A partition is an allocation of storage for a table, backed by solid-state drives (SSDs) and automatically replicated across multiple Availability Zones within an AWS region.
Data in DynamoDB is spread across multiple DynamoDB partitions. As the data grows and throughput requirements are increased, the number of partitions are increased automatically. DynamoDB handles this process in the background.
When we create an item, the value of the partition key (or hash key) of that item is passed to the internal hash function of DynamoDB. This hash function determines in which partition the item will be stored. When you ask for that item in DynamoDB, the item needs to be searched only from the partition determined by the item’s partition key.
The internal hash function of DynamoDB ensures data is spread evenly across available partitions. This simple mechanism is the magic behind DynamoDB’s performance.
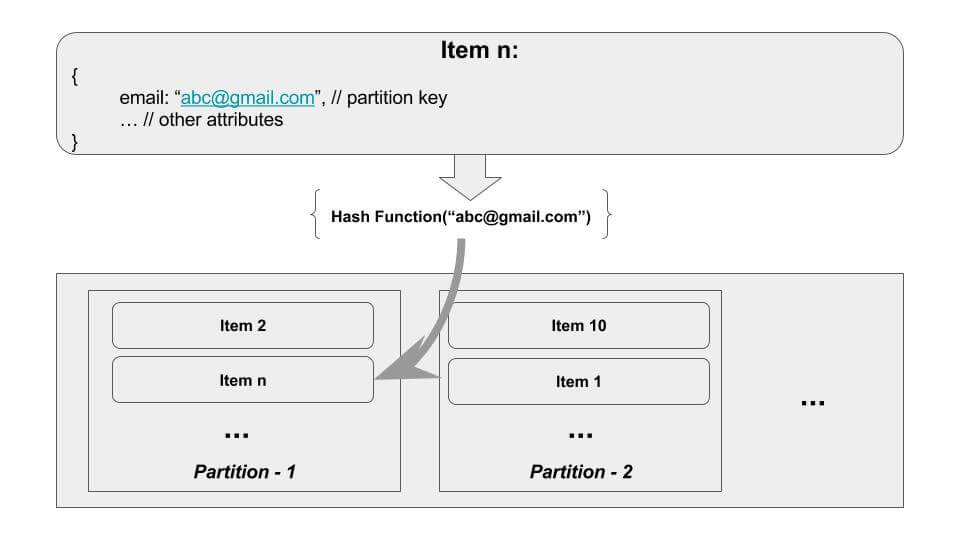
Limits of a partition
The partition can contain a maximum of 10 GB of data. With size limit for an item being 400 KB, one partition can hold roughly more than 25000 (=10 GB/400 KB) items.
Regardless of the size of the data, the partition can support a maximum of 3000 Read Capacity Units (RCUs) or 1000 Write Capacity Units (WCUs).
When and How Partitions Are Created
Taking a more in-depth look at the circumstances for creating a partition, let’s first explore how DynamoDB allocates partitions.
Initial allocation of partitions
When a table is first created, the provisioned throughput capacity of the table determines how many partitions will be created. The following equation from the DynamoDB Developer Guide helps you calculate how many partitions are created initially.
( readCapacityUnits / 3,000 ) + ( writeCapacityUnits / 1,000 ) = initialPartitions (rounded up)
Which means that if you specify RCUs and WCUs at 3000 and 1000 respectively, then the number of initial partitions will be ( 3_000 / 3_000 ) + ( 1_000 / 1_000 ) = 1 + 1 = 2.
Suppose you are launching a read-heavy service like Medium where a few hundred authors generate content and a lot more users are interested in simply reading the content. So you specify RCUs as 1500 and WCUs as 500, which results in one initial partition ( 1_500 / 3000 ) + ( 500 / 1000 ) = 0.5 + 0.5 = 1.
Subsequent allocation of partitions
Let’s go on to suppose that within a few months, the blogging service becomes very popular and lots of authors are publishing their content to reach a larger audience. This increases both write and read operations in DynamoDB tables.
As a result, you scale provisioned RCUs from an initial 1500 units to 2500 and WCUs from 500 units to 1_000 units.
( 2_500 / 3_000 ) + ( 1_000 / 1_000 ) = 1.83 = 2
The single partition splits into two partitions to handle this increased throughput capacity. All existing data is spread evenly across partitions.
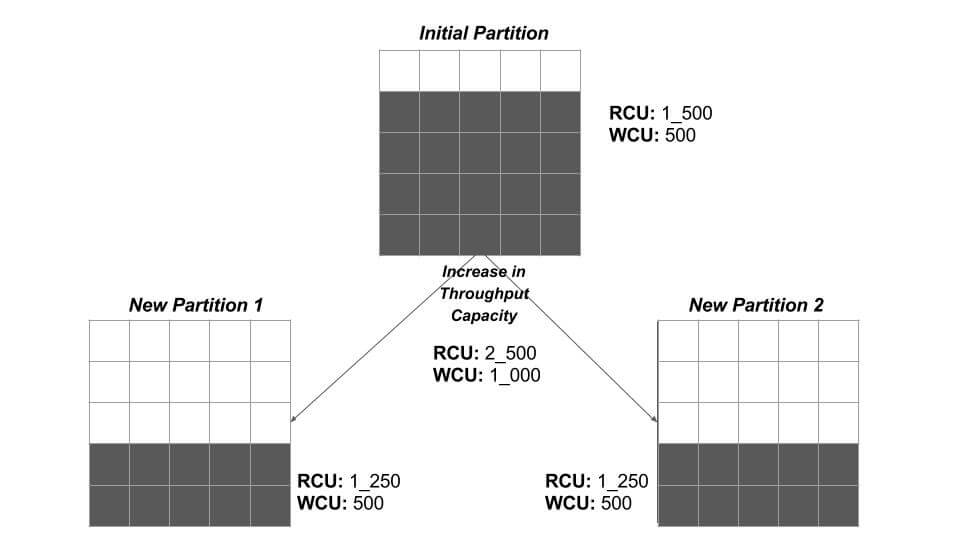
Another important thing to notice here is that the increased capacity units are also spread evenly across newly created partitions. This means that each partition will have 2_500 / 2 => 1_250 RCUs and 1_000 / 2 => 500 WCUs.
When partition size exceeds storage limit of DynamoDB partition
Of course, the data requirements for the blogging service also increases. With time, the partitions gets filled with new items, and as soon as data size exceeds the maximum limit of 10 GB for the partition, DynamoDB splits the partition into two partitions.
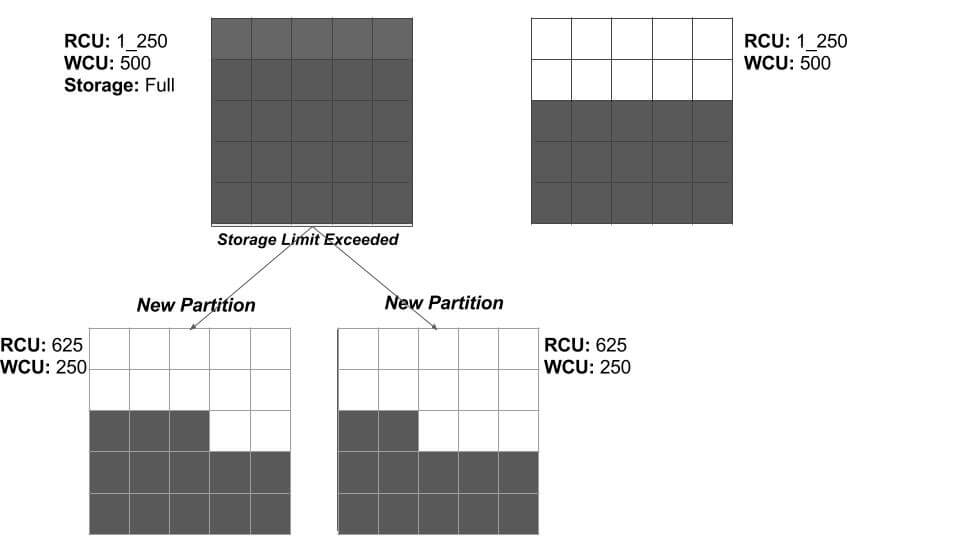
The splitting process is the same as shown in the previous section; the data and throughput capacity of an existing partition is evenly spread across newly created partitions.
!Sign up for a free Codeship Account
How Items Are Distributed Across New Partitions
Each item has a partition key, and depending on table structure, a range key might or might not be present. In any case, items with the same partition key are always stored together under the same partition. A range key ensures that items with the same partition key are stored in order.
There is one caveat here:
Items with the same partition key are stored within the same partition, and a partition can hold items with different partition keys.
Which means partition and partition keys are not mapped on a one-to-one basis. Therefore, when a partition split occurs, the items in the existing partition are moved to one of the new partitions according to the mysterious internal hash function of DynamoDB.
Exploring the Hot Key Problem
For me, the real reason behind understanding partitioning behavior was to tackle the Hot Key Problem.
The provisioned throughput can be thought of as performance bandwidth. The recurring pattern with partitioning is that the total provisioned throughput is allocated evenly with the partitions. This means bandwidth is not shared among partitions, but the total bandwidth is divided equally among them. For example, when the total provisioned throughput of 150 units is divided between three partitions, each partition gets 50 units to use.
It may happen that certain items of the table are accessed much more frequently than other items from the same partition, or items from different partitions. Which means most of the request traffic is directed toward one single partition. Now the few items will end up using those 50 units of available bandwidth, and further requests to the same partition will be throttled. This is the Hot Key Problem.
Surely the problem can be easily fixed by increasing throughput. But you’re just using a third of the available bandwidth and wasting two-thirds.
A better way would be to choose a proper partition key. A better partition key is the one that distinguishes items uniquely and has a limited number of items with the same partition key.
How to avoid the hot key problem with proper partition keys
The goal behind choosing a proper partition key is to ensure efficient usage of provisioned throughput units and provide query flexibility.
From the AWS DynamoDB documentation:
To get the most out of DynamoDB throughput, create tables where the partition key has a large number of distinct values, and values are requested fairly uniformly, as randomly as possible.
In simpler terms, the ideal partition key is the one that has distinct values for each item of the table.
Continuing with the example of the blogging service we’ve used so far, let’s suppose that there will be some articles that are visited several magnitude of times more often than other articles. So we will need to choose a partition key that avoids the Hot Key Problem for the articles table.
In order to do that, the primary index must:
- Have distinct values for articles
- Have the ability to query articles by an author effectively
- Ensure uniqueness across items, even for items with the same article title
Using the author_name attribute as a partition key will enable us to query articles by an author effectively.
The title attribute might be a good choice for the range key. As author_name is a partition key, it does not matter how many articles with the same title are present, as long as they’re written by different authors. Hence, the title attribute is good choice for the range key.
To improve this further, we can choose to use a combination of author_name and the current year for the partition key, such as parth_modi_2017. This will ensure that one partition key will have a limited number of items.
Conclusion
In this final article of my DynamoDB series, you learned how AWS DynamoDB manages to maintain single-digit, millisecond latency even with a massive amount of data through partitioning. We explored the Hot Key Problem and how you can design a partition key so as to avoid it.
Check out the DynamoDB Developer Guide’s Guidelines For Tables and Partitions and Data Distributions for further reading. And remember that the first article in this series, Working with DynamoDB, covers the basics of DynamoDB along with batch operations, and the second article, Querying And Pagination with DynamoDB, explains in detail about query and scan operations, as well as the importance and implementation of pagination.
| Reference: | Partitioning Behavior of DynamoDB from our WCG partner Parth Modi at the Codeship Blog blog. |
