For a specific project we needed a quick way to get the content of a specific URL and check whether a word was present in the text there.
If all we had to scrape were static websites, this wouldn’t be that difficult. We would just get the sources, parse them with jsoup and extract the readable content.
However, a large percentage of the target sites, are single page apps or angular applications, which only show the content after some javascript processing. So we started looking at an alternative way to do this.
First try, PhantomJS
First, we looked at whether we could simply use PhantomJS to get the website and return the content. With PhantomJS this is really simple, and the whole code looks something like this:
var args = system.args;
var webPage = require('webpage');
var page = webPage.create();
page.open(args[1], function (status) {
var content = page.plainText;
console.log('Content: ' + content);
phantom.exit();
});And we can use this minimal script like this:
$ phantomjs test.js https://news.ycombinator.com/ Content: Hacker News new | comments | show | ask | jobs | submit login 1. Outlook 2016’s New POP3 Bug Deletes Your Emails (josh.com) 40 points by luu 2 hours ago | 3 comments 2. 52-hertz whale (wikipedia.org) 148 points by iso-8859-1 5 hours ago | 46 comments 3. What My PhD Was Like (jxyzabc.blogspot.com) 30 points by ingve 2 hours ago | 6 comments ...
Well that was a couple of minutes work, and with a quick minimal API surrounding it, it perfectly matched our requirements, and would be easily embedabble. We can just use PhantomJS to render the page, handle the JavaScript and no more worries. But, unfortunately, after testing a couple of site, we ran into an issue with a number of European sites. The problem was this: the EU Cookie Law (http://ec.europa.eu/ipg/basics/legal/cookies/index_en.htm). This guideline pretty much states this:
What is the cookie law.
“The ePrivacy directive – more specifically Article 5(3) – requires prior informed consent for storage ofor access to information stored on a user’s terminal equipment. In other words, you must ask users if they agreeto most cookies and similar technologies (e.g. web beacons, Flash cookies, etc.) before the site starts to use them.”
Or in other words, before you can use the site, you have to consent that cookies may be used. Most sites implement this through the use of a modal popup, or an overlay at either the top or the bottom. Depending on the country you’re in, this law is more or less enforced (see https://cookiepedia.co.uk/cookie-laws-across-europe for country specific details). In the Netherlands, we’re I live and work and most of our customers are, it’s been pretty much mandated by the government for websites to strictly follow this rule.
So we ran into the problem that instead of getting the real content of the site, we’d sometimes get only the cookie message, or our content contained information that wasn’t relevant. For example see the following site, which provides such a popup:
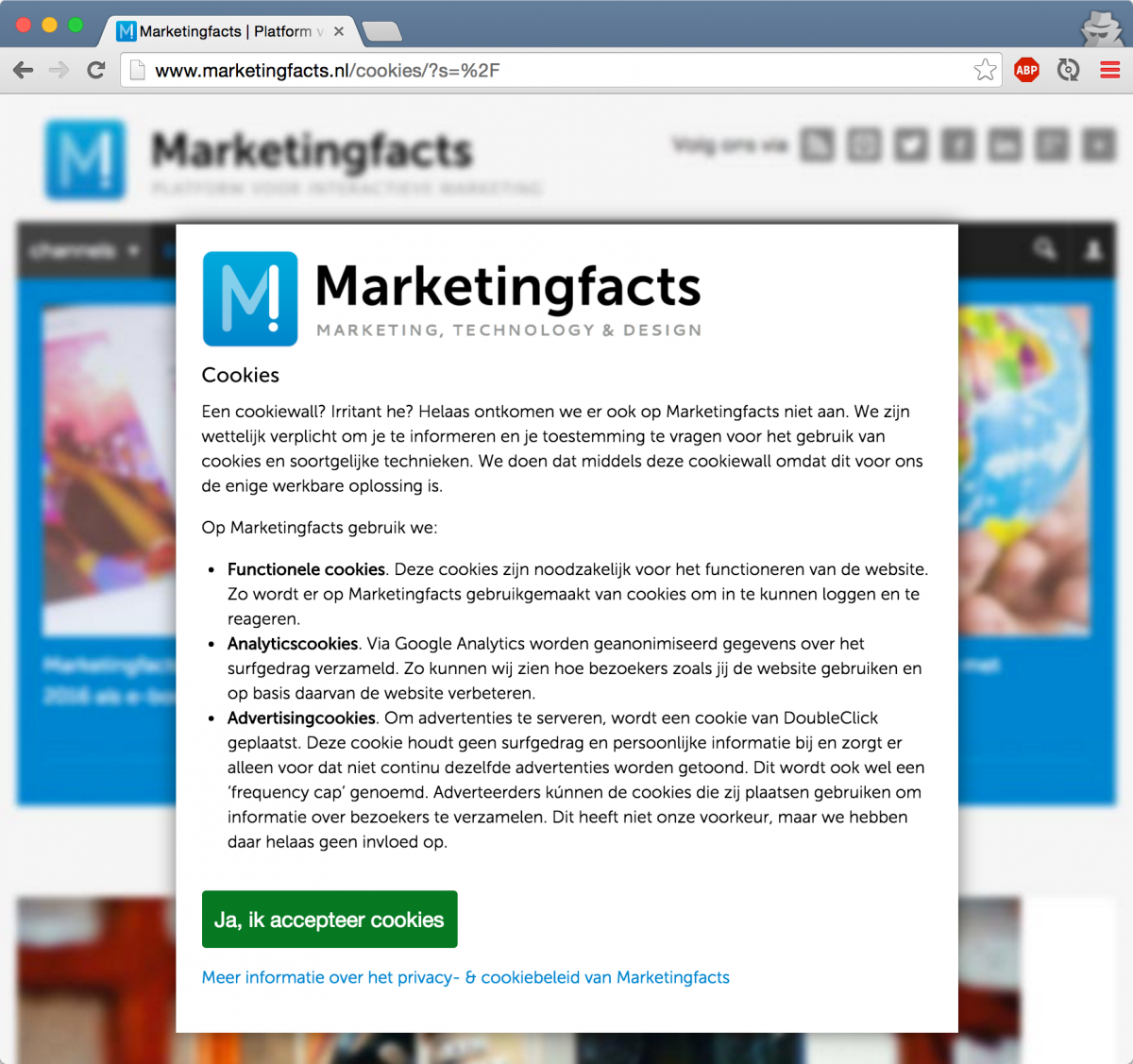
While this was probably created with the best intentions in daily use it is very annoying, and when trying to automate and scrape stuff it makes stuff unnecesary complex.
Luckily though, there is a way we can circumvent most of these popups. By installing the “I don’t care about cookies (http://www.kiboke-studio.hr/i-dont-care-about-cookies/)” extension in your browser, most of these popups and consent forms will just be ignored. So what we’d want to accomplish is running this extension so that we can scrape websites without having to worry about invalid content based on this cookie law. Running Chrome extensions in PhantomJS, however isn’t possible, so we need an alternative approach.
Selenium and Chrome.
Basically what we want is, instead of scripting PhantomJS, we want to script Chrome with this extension installed. Actually doing this is suprisingly easy. The first thing we need is to be able to run and control Chrome. For this we can use ChromeDriver(https://sites.google.com/a/chromium.org/chromedriver/) which is an implementation of the WebDriver specification (https://w3c.github.io/webdriver/webdriver-spec.html) which allows remote control of a specific Chrome instance. When we’ve got Chrome running with the webdriver enabled, we can connect using one of the WebDriver client libraries (http://www.seleniumhq.org/download/) and start scripting our Chrome browser. To start a Chrome enabled webdriver (especially on a headless server, which is where we’d be running this) is a bit cumbersome, so we’ll just use a ready to use Docker image instead.
$ docker run -d -v /dev/shm:/dev/shm -p 4444:4444 selenium/standalone-chrome cbca5a2daf290c72f5771bbc1655e61a7700053ff1e2b95ece5301286692885e ➜ tmp docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cbca5a2daf29 selenium/standalone-chrome "/opt/bin/entry_point" 4 seconds ago Up 1 seconds 0.0.0.0:4444->4444/tcp high_ritchie
This will start up a single node with Selenium and Chrome configured. We can see this is working by opening up a browser and pointing it to the hub url on the exposed port. Note the /dev/shm:/dev/shm part, this is needed to circumvent a bug when running Chrome in Docker (https://github.com/elgalu/docker-selenium/issues/20#issuecomment-133011186).
The Hub url on my local machine is: http://192.168.99.100:4444/wd/hub:
Not that exciting right? Lets run a simple script to see if everthing is working. You can use Selenium with a number of different tools and languages, for this article I’ll use Scala, but libraries are available for a lot of different languages. Let’s look at the code you can use to get a page, and output all it’s text content to the console:
import java.net.URL
import org.openqa.selenium.WebDriver
import org.openqa.selenium.chrome.{ChromeOptions}
import org.openqa.selenium.remote.{DesiredCapabilities, RemoteWebDriver}
import org.scalatest.selenium.WebBrowser
object SeleniumScraper extends App with WebBrowser {
val capability = DesiredCapabilities.chrome()
implicit val webDriver: WebDriver = new RemoteWebDriver(new URL("http://192.168.99.100:4444/wd/hub"), capability)
try {
go to ("http://bbc.co.uk/")
find(tagName("body")) match {
case Some(el) => println(el.text)
case None => println("No body element found")
}
} finally {
close()
quit()
}
}When we run this, we use the Selenium Chrome instance running in our docker container, to fetch the page. The first lines of the output look something like this:
Cookies on the BBC website The BBC has updated its cookie policy. We use cookies to ensure that we give you the best experience on our website. This includes cookies from third party social media websites if you visit a page which contains embedded content from social media. Such third party cookies may track your use of the BBC website. We and our partners also use cookies to ensure we show you advertising that is relevant to you. If you continue without changing your settings, we'll assume that you are happy to receive all cookies on the BBC website. However, you can change your cookie settings at any time. Continue Change settings Find out more Accessibility links Accessibility Help Sign in BBC navigation News Sport Weather Shop Earth Travel More Search the BBC SATURDAY, 27 FEBRUARY Hillary Clinton secures a big win over Bernie Sanders in the South Carolina primary, the latest battleground for the Democratic presidential nomination. ...
While this is already pretty good, we can see the cookie law in action here. While on the BBC site it doesn’t hide any content or prevent you from continuing, it still shows us a popup and could give us false positives when we want to search for words occuring on a specific page.
Adding extensions to chrome using selenium
I’ve mentioned the i-dont-care-about-cookies plugins earlier. If we could install this plugin in our automated browser, we could use the plugin’s filtering to remove and ignore these cookie messages. To install a plugin automatically in chrome we could follow the procedure from here: https://developer.chrome.com/extensions/external_extensions#preferences. But that would mean creating a new docker image with the correct settings. An easier approach, however, is offered by Selenium. First, though, we need the plugin as a crx archive. For this you can just use http://chrome-extension-downloader.com/ to download the plugin as a file from the filestore. Once you have this file, just add the following to your selenium script and the plugin will be automatically loaded whenever your script starts.
val capability = DesiredCapabilities.chrome()
val options = new ChromeOptions();
options.addExtensions(new File("/Users/jos/Downloads/idontcareaboutcookies-2.5.3.crx"))
capability.setCapability(ChromeOptions.CAPABILITY, options)Now when we run this same simple script again, we see the following:
Accessibility links Accessibility Help Sign in BBC navigation News Sport Weather Shop Earth Travel More Search the BBC SATURDAY, 27 FEBRUARY Huge win for Clinton in South Carolina Hillary Clinton secures a big win over Bernie Sanders in the South Carolina primary, the latest battleground for the Democratic presidential nomination.
As you can see, this time, the specific cookie message is ignored.
So with just a couple of simple steps we can scrape websites, and make sure we only get the core content by using an extension. We can of course also use this to run other plugins such as adblockers.
| Reference: | Website scraping using Selenium, Docker and Chrome with Extensions from our WCG partner Jos Dirksen at the Smart Java blog. |

Thank you for the article. But is there a way to make this work with Chrome in headless mode?